The 2 Main Problems in Machine learning Overfitting and underfitting are the two most typical machine learning problems that affect model performance. Before we get into overfitting and underfitting, let’s establish some crucial concepts that will help us understand this topic better:
1.Signal: It refers to the data’s true underlying pattern, which the machine learning model may learn from.
Noise is unnecessary and useless input that reduces model performance.
2.Bias: Bias is a prediction inaccuracy caused by oversimplifying machine learning methods.
Alternatively, it is the difference between the projected and actual numbers.
Variance: If the machine learning model performs well on the training dataset but does not perform
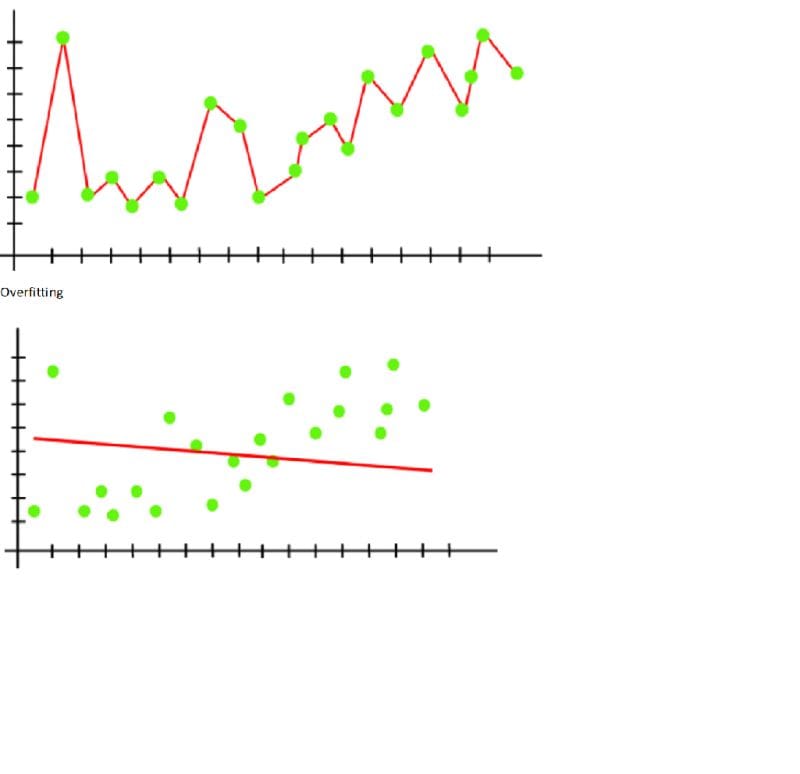
Overfitting -Overfitting in machine learning
Overfitting occurs when our machine learning model seeks to cover all or more of the data points in a given dataset. As a result, the model begins to cache noise and erroneous values from the dataset, all of which impair the model’s efficiency and accuracy. The overfitted model exhibits low bias and large variance.The odds of overfitting rise as we train our model. It indicates that the more we train our model, the greater the likelihood of it becoming overfitted.
First Problem in machine Learning Model:-
Overfitting occurs when our machine learning model seeks to cover all or more of the data points in a given dataset. As a result, the model begins to cache noise and erroneous values from the dataset, all of which impair the model’s efficiency and accuracy. The overfitted model exhibits low bias and large variance.
The odds of overfitting rise as we train our model. It indicates that the more we train our model, the greater the likelihood of it becoming overfitted.
How to avoid the Overfitting in Model -Regularization techniques for overfitting
Both overfitting and underfitting degrade the performance of the machine learning model.
But the main cause is overfitting, thus there are certain techniques to limit the likelihood of overfitting in our model.
By Using below we can avoid the Overfitting
- Cross-Validation
- Training with more data
- Removing features
- Early stopping the training
- Regularization
- Ensembling
- Underfitting
Underfitting-:
The second machine learning problem is underfitting, which occurs when our machine learning model fails to grasp the data’s underlying trend. To avoid overfitting in the model, the feeding of training data might be stopped early on, resulting in the model not learning enough from the training data. As a result, it may fail to identify the best fit to the prevalent trend in the data.
- An underfitted model has high bias and low variance.
- How to avoid underfitting:
- By increasing the training time of the model.
- By increasing the number of features.
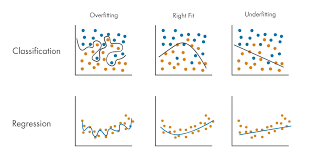
Visual Representation of Underfitting and Overfitting:
- Underfitting: Underfitting is when a straight line attempts to fit curved data, resulting in the absence of essential patterns.
- Overfitting is a model that precisely follows each point, resulting in a highly complex decision boundary that captures noise as if it were a pattern.
- A good fit is a model that strikes a compromise between complexity and precision, capturing true patterns while minimizing noise.
- Bias-variance tradeoff:
• High bias leads to underfitting due to the model’s simplicity and inflexibility.
• High variance can cause overfitting, resulting in a complicated model that over-adapts to training data.
The purpose of a machine learning model is to strike the proper balance between bias and variance, ensuring that it generalizes well to new data. Regularization techniques and cross-validation are critical for preventing both underfitting and overfitting. realizes well to new data. Regularization techniques and cross-validation are critical for preventing both underfitting and overfitting.
Key Takeaways:
• Overfitting occurs when a model is overly complex and includes noise (low bias, large variance).
• The optimal model strikes a compromise between capturing important trends and generalizing to new data.
Overfitting and Underfitting: The Key Factors of the Machine Learning Model Evalutaion
Artificial intelligence has changed different technologies, although, it depends on different models in the technological solutions. Among the questions that are most central to data scientists, two of them that have to do with predictive modeling are overfitting and underfitting. So, one must get deeper knowing about these concepts and their consequences, and how they can be prevented.
Understanding Overfitting
Overfitting is when a machine learning model learns the noise as well as the salient features of the data input This makes the model extremely good on the training data set but very poor on new data set.
The opposite of overfitting isUnderfitting is similar to a student memorizing examples in a text book and hence performs very well in mock examinations but poorly when faced with real life problems.
Explaining Key Characteristics of Overfitting
Most often, overfitting is an identification of a model where the model performs very well especially when tested on the training data set but poorly on the validation or even the test data set. The reason for such disparity is that the model is over-parameterized containing many degrees of freedom that can fit the training dataset perfectly. The model ends up causing worse performance during prediction of new datasets due to lack of generalization.
Causes of Overfitting
Several factors can contribute to overfitting:
• Excessive Complexity: When the model complexity implemented or its parameters exceed the quantities of available data.
• Insufficient Data: If the training dataset is too small, the model tends to over-fit or instead fit that noise in the set.
• Unnecessary Features: They are showing that too much information can be represented also means that an excessive amount of features, which will only slow down the particular process or system.
• Noisy Data: Data sets with large amounts of error or intrusion that contain irrelevant info also increases the overfitting issue.
Understanding Underfitting
These results occur when a model is simplistic and cannot adequately capture the relation of the data. This leads to poor accuracy on training and testing datasets as it becomes evident in the subsequent sections. An underfitted model in signal processing
Underfitting Characteristics:
Most of the time, underfitting models exhibit low accuracy in most of the datasets since they cannot learn the datasets’ complexities. While overfitting involves the model learning all sorts of things, underfitting results from a case where the model ends up learning too little.
Causes of Underfitting

Several factors contribute to underfitting:
• Overly Simplistic Model: Applying fixed structures for a solution that fits dynamic equation systems.
• Insufficient Training Time: Halting the training at a wrong time will mean that the model is not optimized fully is in its least ‘fit’ state.
• Lack of Features: If the dataset does not have enough detailed features, the model cannot even learn the right details.
• Inappropriate Parameters: A Looper hyperparameter pair ( α, λ) in which α represents a learning rate for gradient descent and λ is a regularization term must be chosen well: otherwise, the model would be too limited.
Balancing the Trade-off
The process of decision making or learning with the help of a computer is guided by certain aims and objectives where the primary aim of developing machine learning is to address the problem of overfitting as well as underfitting. This is normally done by designing a model which the results show good training and is equally good on unseen data. Entailing cross validation, feature selection and regularization enables one arrive at this sweet spot.
Major Strategies to Avoid Overfitting
1. Cross-Validation: Such cross validation methods help in making sure that the model that has been developed will also be tested on many subsets such as k-of them.
2. Regularization: it helps to avoid the model become over-fitted by using L1 or L 2 softmax in the formula of penalty terms.
3. Pruning: It is worth defining two of the operations used in decision trees: Pruning: makes the decision tree easier.
4. Dropout: In general, dropout layers are circuits that are disconnected during training so that the network will not over-rely on specific routes.
These are the critical steps towards preventing underfitting Strong strategies to use when developing the model include:
1. Model Complexity: Approaches that are not linear can be chosen, for example, transition from linear regression to the decision tree.
2. Feature Engineering: Putting several features or creating polynomial terms build up the data set.
3. Hyperparameter Tuning: By either lowering the regularization strength or by increasing the training epochs one can enhance the performance.
Real Life Overfitting and Underfitting Examples
To make these concepts more concrete consider an example in healthcare predictive modeling. Let us assume that you want to develop a model, which provides the probability of patient readmission given demographic-clinical characteristics. If a model is over fitted then it will pick up noise, for instance, small frequencies that are present in the given training data and this will lead to a wrong prediction of a new patient group. On the other extreme, an underfitting model could miss significant relationships completely, including the relationship between different symptoms and high readmission rates, characteristic of poor model performance for all the datasets.
Another example speaks about overfitting when in the sphere of forecasting market valuing, a model will look for the short-term fluctuations as for the trends which leads to unpredicted and doubtful results. On the other hand, an underfitted model could simply disregard the fluctuations in stock prices as an overfitting model would, and come up with flat predictions that are not helpful at all.
Overfitting and underfitting have devastating effects on the performance of models that are employed in the estimation of parameters, and consequently have far reaching implications on the model implications.
These are some of the issues that any data scientist should know the consequences and ramifications of these issues. The common problem associated with overtraining is identification of cases which the model performs very well during training but poorly during deployment. On the other hand overfitting leads to uniformly bad performance in the future and the model is considered useless. Both scenarios pose the risk to the accuracy and credibility of AI driven solutions including their application in the important industries including the healthcare, finance, and self propelled vehicles.
Conclusion
The problem yet to be solved in good machine learning is the balance between overfitting, which arises when the model is too complex, and underfitting which arises when the model is too simple. This is not a possible task to achieve without comprehensive dataset cleaning, the application of sound statistical analysis methods, and refinements. With these concepts in place, data scientists may be able to devise the accurate and realistic prediction models, making the full sense of machine learning field to solve real society issues.
It is important to note, the discussion of pitfalls such as overfitting and underfitting models are not merely an academic exercise but rather staples for assuring the success of machine learning models in an actual applications environment. These issues highlight the basic cost benefits that data scientist cannot avoid as they define key features of the model designing and implementation.
This paper considers the manifestation and impacts of overfitting and underfitting, and the general notion of goodness of fit towards the broader problem of employing machine learning algorithms.
Both over fitting and under fitting are concepts that are not isolated to the act of attempting to build a machine learning algorithm but are related to how humans process information. For example, overfitting translates into overcomplication, which literally means overemphasis on minor issues. On the other hand, underfitting represent the other extreme which expose the risk of applying oversimplified model where important aspects of the problem are simply excluded and the solution is either inadequate or inconsequential.
Consequently of these issues, various vocations including healthcare, finance and education are at risk. An overfitting medical diagnosis model may predict certain ailments in a patient even when they are not existent making the patient have undue panic when there is really no cause to fear. In finance, usage of such models renders too much confidence in certain market forecasts thus incurring serious losses. Education can be considered as oversimplified if it does not look at a specific group of students who need help and continue to promote inequity.
So, addressing these problems, machine learning practitioners have a chance to develop the models which are not just accurate, but also fair, on a larger scale and robust.
The reason such balance is important
The degree to which model can fit data on the one hand affects its capacity to fit data it has not being trained on on the other hand. It was also mentioned that generalization is the greatest goal of machine learning because it makes it possible to use learned lessons from past data in changing environments. Preventing this allows models to remain applicable, and any time and resources spent acquiring, cleansing, and interpreting data are rendered useless.
Furthermore, this balance defines the level of a data scientist or machine learning engineer’s maturity. It also shows the capacity to claim having an appropriate degree of technicality while at the same time not losing the essence of its realistic applicability. The ugly between overfitting and underfitting is not in sticking to the algorithm blindly but in trial and error, good scrutiny and general enlightenment on the problem in question.
Over-fitting and Under-fitting: Ethical Issues
Apart from four technical factors, ‘overfitting’ and ‘underfitting’ also contain an ethical facet. In areas such as criminal justice, this training data is likely to create overly complex models that would continue to prejudice one group against the other. Lack of complexity entails that underfitted models can result to injustices and discriminator checker ability to capture every human behavior.

Ethical machine learning call for the developers to keep watch on these risks that are associated with the machine learning algorithms. By managing the processes that result in overfitting and underfitting, including problems with bias in the data sets, or feature engineering, practitioners can design human orientated and competent models.
Measures for Enhancement of a Continuous Improvement Programme
Despite this, one has to continue to monitor the machines learning models in existence to try and strike the right balance and efficacy. This process, often referred to as model maintenance, involves the following steps:
1. Regular Performance Evaluation: Fine tuning on different sets of data at different times enables validation of its ability to generalize.
2. Feedback Loops: Integrating user ratings can also show limitations of the proposed model as to the discrepancies of overfitting or underfitting.
3. Retraining with Updated Data: In data driven world new sets of data come up from time to time and thus training the model with new data is beneficial for it.
4. Explainability and Transparency: Interpreting models for decision making enables the stakeholders to prevent issues of overfitting or underfitting before they occur.
This way, machine learning is no longer seen as a one-time project but as a continuous process, and data scientists can thereby avoid that the model’s performance slowly deteriorates over time.
The First Factor: The Role of Emerging Technologies
Overfitting and underfitting issues are becoming easily manageable, due to developments in the machine learning frameworks and tools. Machine learning methods like the AutoML and the optimization algorithms are being utilized by practitioners to engineer models that are less bias by nature.
As an example, hyperparameters setups, feature array, and validation can all be accomplished in AutoML platforms and the chances of the developers inputting wrong parameters are minimized. Moreover, there are the ensemble learning methods that use several models included bagging and boosting and get less different, adequate prediction system.
at the same time, progress in unsupervised learning is improving the preprocessing of data and thus can reduce cases of underfitting by extracting more features from raw data.
The Role of the Philosophy in the Provision of Machine Learning Balance
The essence of machine learning, therefore, can be summarised most usefully as a process of negotiation between a set of priorities. The struggle to avoid overfitting and underfitting reflects fundamental dilemmas of business and life, such as flaxiness and stiffness, creativity and stability, and dreams and reality. This philosophy emphasizes the fact that its understanding requires both art and science of machine learning.
Although mathematics and algorithms form the platform on which the models are built, chances are that you often apply heavy doses of intuition and creativity when designing the models. Besides, mastering the use of technical methods themselves, a good machine learning practitioner also understand how and why they are used. So it is the ability to seek reason in data and the ability to apply human discretion that sets high-performing models apart from utilitarian ones.
Future Course of Study and Research avenue
There are new ideas in the machine learning field to deal with overfitting and underfitting issues and some of these are discussed in the subsequent sections. Some of the most promising areas of research include:
•Meta-Learning: This papers encompasses areas of constructing models with a capacity to learn how to learn; that is, being capable of performing new tasks with little training.
•Federated Learning: Compared with traditional centralized training with a centralized data source, federated learning is less likely to overfit the model while protecting privacy by training models based on distributed and decentralized data sources.
•Explainable AI (XAI): Methods that facilitate the enhanced interpretations of models assist in finding out when overfitting or underfitting happens and the reason behind it.
•Data Augmentation: Underfitting can be corrected by creating synthetic data that will replicate realistic distribution of variation for training the model while adding noise to the dataset.
As mentioned above, as the advancements in methodology and applications go on, there will be a better disconnection between the theory and practical application in the ML democratization process, therefore creating the reliability of the results in different industries.
Make it a Call to Action for Practitioners
Finally, the issues of overfitting, or underfitting are the concerns to be addressed by the practitioners who create and implement the machine learning. By adopting the thinking of more about quantity or precision or accurate over precise and concentrating with an ethical issue rather than speed, the data scientist can be certain that the models that they are going to develop are going to help positively to the society.
This journey cannot be prosecuted without embracing learning, team work, and appreciation for knowledge. Machine learning is an area where nobody wants to keep secrets, and when practitioners open themselves up to the wider community, they will be better armed to face the threats posed by overfitting and underfitting more effectively.
Closing Thoughts
Lastly, overfitting and underfitting pertain to two of the important issues of machine learning, which when looked through a conceptual vantage point, gives solutions a new perspective. They look to inform us that, although data and algorithms are great, they are nothing more than the representation of those behind them. When tackling these difficulties, we must do so with curiosity, ensuring rigorous critical thinking and being held to responsibility – this, we can achieve the actual potential of machine learning and advancements in the years to come.
This journey, the journey over the fine line between overfitting and underfitting, if not the journey of modeling at all, is one that is iterative and ongoing—perhaps the very nature of learning.
1 thought on “2 Issues-Degrades Machine learning Model performance”