Machine learning has transformed industries, not only in how companies operate, but also in how they build solutions. The uses of machine learning are almost limitless, from consumer prediction to disease diagnosis. However, it is quite a challenge to perform a successful machine learning project. Each of the stages needs careful planning, technical proficiency and a clear definition of aims.
This guide, discussing six steps necessary to execute a machine learning project is presented, where, not only best practices are given, but also the usual errors are indicated, and their practical solutions are to be implemented. At the conclusion the learner will be equipped with a plan for how to build machine learning solutions that are of practical value.
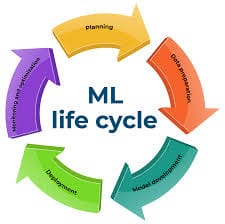
Steps for machine learning project.
- Project Initiation
- Data Exploration
- Data Processing
- Model Development
- Model Evaluation
- Model Deployment
Step 1: Define the Problem and Understand Objectives
A solid foundation for any machine learning project is a clearly stated and well understood issue. Before examining datasets and/or algorithms, there is an opportunity to define the scope of an experiment. The process of learning about the problem includes, but is not limited to, understanding what business or societal problem you are trying to solve, what you want to achieve, and how that relates to the strengths and limitation of machine learning.
Reduce the number of patrons who stop buying products/services). The machine learning problem is then translated into a classification problem in which the model determines whether the customer belongs to a churn class or not on the basis of historical data.
At this stage, collaboration with domain experts is crucial. These stakeholders contribute with key pieces of information about the context of the problem, guaranteeing that the machine learning strategy is appropriate for real world needs. Additionally, you need to define metrics for success. In the churn case, an appropriate success may be thought at the price of the accuracy and the recall of the model, so as to correctly “sniff out” the at-risk clients, without to over-predict churn.
Step 2: Collect and Prepare Data
Data lies at the heart of machine learning. The correct data, collected and of good quality serve as the critical factor in project success. Begin by identifying data sources. They can involve internal databases, external APIs, publicly accessible data, or streams of real-time data. Examples include but are not limited to) purchase records, customer demographic data, and service logs, in a case study of customer churn project, and so on.
Once data is collected, the preparation phase begins. This covers data cleaning and preprocessing to address variability, missing values and multiple instances. Data cleaning makes the data valid and trustable. For example, if customer age data has missing values, it might be necessary to impute the missing values with statistical techniques or expert knowledge.
Normalization and standardization are also key preprocessing steps, particularly with numerical data. These methods guarantee uniform scaling of features, such that algorithms do not unfairly weight any of the variables. Also, categorical data have to be discretized to the numerical form, typically using methods such as one-hot encoding or label encoding.
Data preparation starts by dividing the dataset into training, validation and test sets. This split allows you to evaluate the model’s performance effectively while avoiding overfitting, a common pitfall in machine learning.
Step 3: Choose the Right Machine Learning Algorithm
Following data preparation, the next step is to select a suitable machine learning algorithm. Algorithm selection is determined by the nature of the problem, the nature of the data, and requirements of the output. Classification problems, e.g., customer churn prediction, often make use of algorithms (e.g., logistic regression, decision trees, or support vector machines). Regression tasks (e.g., sales forecasting) rely on techniques including linear regression or gradient boosting.
Following traditional machine classifiers, deep learning models, e.g., neural density, since they appear to solve complex problems such as image recognition and natural language processing [1, 2]. In the case, for example, convolutional neural networks (CNNs) are capable of processing visual data, and recurrent neural networks (RNNs) are suitable for sequential data such as a time series or text.
The complexity-interpretability trade-off is a question that needs to be taken into account when choosing algorithms. Simpler models, like decision trees, are easier to explain and interpret, making them suitable for applications where transparency is crucial. On the other hand, sophisticated models, e.g., ensembles or neural networks, afford accuracy at the expense of interpretability.
Step 4: Train the Model
In this stage the machine learning system is trained to recognise patterns in the data (model building). This method consist on putting the training dataset in the algorithm, so that it can readjust parameters and reduce errors. Training is iterative process, in which weights or coefficients are updated in order to improve estimations.
In contrast to parameters learned by the algorithm during training, hyperparameters are defined ex ante before training starts. For example in the case of e.g., neural networks, learning rate and number of layers are hyperparameters that need to be adjusted to obtain a good result. Methods such as grid search, or random search can help to find the optimal hyperparameter values.
Model training also needs computational power, especially in cases where the data set is large or the algorithm is sophisticated. Using cloud platforms and GPUs, the training process can be significantly sped up.
Step 5: Evaluate and Validate the Model
Bootstrapping model performance, both on the validation set and the test set, is paramount after the model is built. In this step it is certain that the model has a good generalization to previously seen data and that it does not overfit to data included in the training.Common evaluation metrics vary depending on the problem type. In contrast, regression problems usually involve mean squared error (MSE), mean absolute error (MAE), or R-squared (R2).
Building block validation, e.g., cross-validation, is equally important in evaluating the robustness of a model. In k-fold cross-validation the data is split into k-parts and k-fold training and validation of the model is performed using each of them as a validation data-set, once.
Furthermore interpretability-tools e.g., SHAP (SHapley additive exPlanations) or LIME (Local Interpretable model-agnostic Explanation of probability) can also be used to investigate the rank of the variables and reveal the mechanism of an intelligent prediction with those models. These tools are also particularly relevant in applications through optical, i.e., transparent media, such as healthcare or finance.

Deploying the trained model into production is the last step of a machine learning project. Deployment in this context means embedding the model within the existing systems/apps in such a way that the model can produce real-time predictions or decisions.
Deployment strategies depend on the use case. For example, batch processing might be exploited for modeling applications, e.g., churn prediction where the predictions should be computed serially. On the other hand, real-time inference is the heart of applications such as fraud detection, in which fast answer is a necessity.
Monitoring the model post-deployment is equally important. Data distributions can evolve with time as a result of changes in user action or in other events, a phenomenon named as data drift. Continuous performance monitoring of the model and continuous iterative retraining of the model with new data ensure the accuracy and the usefulness of the predictions.Tools (e.g., MLflow, Kubeflow) can help with deployment and monitoring, offering end-to-end machine learning based model solution for production.
Machine Learning -Following these steps systematically ensures that your machine learning project stays on track, producing meaningful, actionable results.
Challenges and Best Practices
While the six steps provide a scaffold, machine learning projects often face data quality issues, the interpretability of models and ethics. Addressing these challenges requires a combination of technical expertise, domain knowledge, and adherence to best practices.
In particular, data privacy and compliance requirements associated with regulations such as GDPR are of paramount importance to the healthcare and finance industries, and so on. Furthermore, if explainable AI methods could facilitate creating trust in ML models in high risk situations, they could be meaningful—in principle—in high risk applications because in some medical or related fields trust in ML models may need to be developed (e.g., radiomics).
Adopting a systematic approach and applying best practices, companies are able to effectively address these aspects and achieve the full benefit offered by machine learning.
Advanced Problem Definition: The Cornerstone of Success
• What factors influence customer churn?
What are the ways in which intervention can be instigated before the customer decides to move on?
There is a cost-benefit trade-off of holding a customer versus acquiring a new one, although it differs among industries and businesses.These questions drive the project and set the stage for subsequent work such as feature selection and model assessment. In addition, problem definition may include finding the right balance between business requirements and technical limitations. The stakeholder engagement process guarantees that the machine learning model provides concrete and usefull insight, as opposed to just general results.
The Role of Domain Knowledge in Data Collection
Data collection is, in many ways, overlooked (we underestimate its importance) but it can be win or lose in terms of whether a project succeeds or not. In addition to the ability to identify data sources, domain knowledge has a critical role to play in data usability, but also in data relevance and data quality (e.g., filling in missing terms in the data source terms). As an example, for medical applications, the selection of patient demographics, medical histories, and diagnostic test results as features necessitates close collaboration with medical experts.
In addition, ethical issues should be considered when data is collected, particularly for industries that have strict regulation, such as the finance and healthcare sectors. Regulatory data compliance (i.e., GDPR-General Data Protection Regulation and HIPAA-Health Insurance Portability and Accountability Act) is not–and can’t be done by decision. However, these techniques of obfuscation and encryption are warranted in order to preserve privacy when machine learning application is being used on the generated data set.
Data Preprocessing: Tackling High-Cardinality Variables
Although classical preprocessing methods, such as missing value and numerical feature scaling, are relatively familiar, there are data with some peculiar issues. Yet, the number of categories of high-cardinality categorical variables (i.e., categorical variables with a relatively large number of unique categories) may result in increased dimensionality by, e.g., employing one-hot encodings of, e.g., categorical variables.
For instance, a dataset with one feature having thousands of items and so on. One-hot encoding will produce tens of thousands of binary columns (i.e., binary columns), too much data to work with. Other methods, e.g., frequency encoding and target encoding, lead to efficient solutions. Frequency encoding maps each category to how many times it occurs, while target encoding maps categories to their group mean based on a target variable.
Moreover, data imbalance has to be identified and dealt with in classification problems must be the situation. Oversampling, using synthetic minority over-sampling technique SMOTE or under-sampling the majority of classes, can address the problem of over-representation that leads to biased models favouring the majority of classes.
Algorithm Selection: Balancing Complexity and Interpretability
Picking however, the algorithm is not just a question of picking the right model. The balance among the complexity, interpretability, and scalability of an algorithm is the selection criterion for an algorithm. Decision trees and linear regression model, for instance, are also easy to explain and, therefore, available in cases in which a high degree of interpretation is required. In, however, when high accuracy is required, as in fraud detection or recommendation systems, it is possible to use sophisticated models, such as random forests, gradient boosting, or deep neural networks, i.e.
Emerging trends in machine learning also influence algorithm selection. As an example, transfer learning facilitates use of pre-trained models to perform special tasks in a time- and resource-efficient manner. Transfer learning by leveraging pre-trained models (e.g., BERT in natural language processing, or ResNet in image recognition) demonstrates transfer learning’s superiority for time estimation reduction.
Hyperparameter Tuning: Beyond Grid and Random Search
Model training is iterative and hyperparameter tuning has a significant impact on performance. Although grid search and random search are the usual approaches, more sophisticated ones, such as Bayesian optimization and automated machine learning (AutoML), can be more effective. Bayesian optimization sequentially adjusts hyperparameter values, by weighing exploration (new hyperparameter settings) and exploitation (improving promising ones).
AutoML-powered tools (e.g., Google AutoML, or H2O.ai) take care of hyperparameter tuning step automatically and thus lead to results as good as humans. These tools also include feature engineering and model validation, thus making the machine learning pipeline less complex.

on the other hand, monitoring convergence during training is critical to avoid overfitting or underfitting. Techniques, e.g., early stopping stop training after performance on a validation set improves no more, optimizing for bias/variance.
The Evolving Landscape of Model Evaluation
Model evaluation extends beyond calculating standard metrics. In high-arousal scenarios e.g., autonomous driving or medical diagnosis) reliability metrics e.g., calibration curves or confidence intervals) and interpretations are also significant. Calibration curves allow to assess if predicted probabilities align with actual/observed outcomes and properly assure the validity of the model’s confidence.
Explainability tools have gained prominence in model evaluation. Method such as SHAP (SHapley Additive exPlanations) provides an answer by delivering feature importance scores, that is, what contribution each of the input variables does to prediction. Examples include, in a credit scoring model, SHAP could demonstrate income and credit history are the top effectors in the loan acceptance process, which would increase stakeholder confidence in the system.
The Challenges of Deployment in Real-World Settings
Deploying a machine learning models to the production is typically a complex task, usually. A typical problem is to “bring the model” into ongoing workflows and systems. E.g., Predicting product demand model needs to integrate with stock management software through APIs or by middleware solution.
Real-time inference introduces additional challenges, especially to applications that have low-latency prediction, e.g., fraud detection. By exploiting technologies like edge computing, delay can be minimized by performing local data processing rather than sending data to central servers.
Model monitoring and retraining are crucial to maintain continuous performance both during and after deployment. Data drift (temporal changes in the distribution of the data) has been shown to degrade model performance. The adoption of automatically operating monitoring systems that retrain the model in case of performance deterioration is guaranteed to keep the model operational in future situations.
Addressing Ethical and Societal Implications
Ethical concerns permeate every phase of a machine learning project. As the process steps from data-skewed to black-box decision making, a series of pitfalls may result in fairness and accountability breaches in machine learning systems. For example, a hiring algorithm trained on historical data might inadvertently perpetuate biases against certain demographic groups.
Bias mitigation has to be taken by way of pro-active actions, e.g., scrutinizing data to what extent they are representative, as well as fairness aware machine learning considerations. Subsequently, interpretability frameworks also assist to ensure that explanations of decisions are both understandable and justifiable, for example, in controlled environments.
The societal implications of machine learning also demand attention. Use is promoted, not only in the short term, but also for the long term repercussions for stakeholders and communities.
Examples of such approaches for federated learning are, for example, decentralized training of models on a cluster of devices or groups of devices/organizations without handing over the raw data, for instance. This approach enhances privacy while leveraging diverse datasets.
Few-shot and zero-shot learning are strong methods for situations where very little labeled data is available. These methods permit, for instance, the application of learning models to generalise with a few samples, and thus reduce the requirement for extensive training sets.
Furthermore, the maturity and the recent growth of generative AI technologies, i.e., GANs (Generative Adversarial Networks) is a borderline case of what machine learning project can achieve. Generative models are paradigmatic of AI’s innovation for synthesis of realistice synthetic data, art, and music, etc.
A Forward-Looking Conclusion
A machine learning project is equally as about technical competence as it is about strategic vision and moral obligation. By mastering the six steps—problem definition, data preparation, algorithm selection, model training, evaluation, and deployment—you can navigate the complexities of machine learning with confidence.
In the future, the evolutionary integration of intelligent technologies (e.g., AutoML, federated learning, and explainer tools) will continue to be a trend to support machine learning access and use by a wider set of organizations. At the same time, navigating the ethical dilemmas and societal implications so that machine learning would do so in the real world will remain of critical importance.
If you begin work on machine learning projects, bear in mind that model accuracy is only one measure of success, among other factors, and that the real measure of your impact is in the tangible value of your solutions. Following through with good practices, adopting innovation, and focusing on ethics, you can design ML systems that lead to progress and enhance human life.
Conclusion
Machine learning project is an adventure that needs patient planning, teamwork, and technical experience. From setting out the problem to the deployment of the model, each one of those steps plays its part in the ultimate outcome.By following the six steps outlined in this guide—defining the problem, collecting and preparing data, choosing the right algorithm, training the model, evaluating its performance, and deploying it into production—organizations can harness the power of machine learning to drive innovation and deliver meaningful results.
The recipe for success is not simply technical implementation of the algorithm, but a deep understanding of the problem domain and the translation of machine-learning solutions into the corresponding real-world objectives. With the growth of machine learning, putting aside an organised, deliberate process will guarantee that projects are more than just a success story and actually do the job.
1 thought on “6 Steps towards a Successful Machine Learning Project”