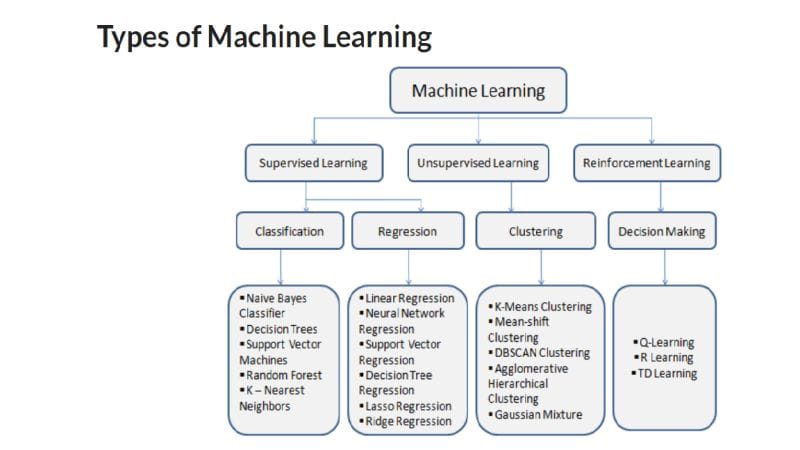
DataScience Machine Learning Supervised Learning is a class of Machine learning where the model is trained on a labeled data set. It is referred to as “labeled” because each of the samples used for training contains the attendant correct output. The aim of supervised learning is to get a model to learn how to map the input data to the proper output in order to label future data sets.
1. DataScience- Machine learning Linear Regression Algorithm
- Use Case: Regression analysis is used for tackling problems where the output is numerical and the data is either continuous or occasionally binary (e.g., predicting house prices, temperature).
- Concept: Linear regression as the name implies tries to predict the relation between two variables by using a line chart that passes through the observed data points.• where y is the dependent variable, xxx is the independent variable, β0 is the intercept, β1 is the pitch measure and ϵ or ε is residual error.once Linear retrogression attempts to model the relationship between two variables by fitting a direct equation to the observed data.
- The formula is: y=β0+β1x+ϵy or y=mx+c
- where y is the dependent variable, xxx is the independent variable, β0\beta_0β0 and β1\beta_1β1 are coefficients, and ϵ\epsilonϵ is the error term.
2. DataScience Machine learning Logistic Regression Algorithm (Classification works)
- Use Case: Two folded tasks (e.g., spam or not spam, sick or not a sick).
- Concept: In logistic regression the outcome variable is the probability that a given input will fall under a certain class. It uses the logistic function (sigmoid) to map the output to a probability value between 0 and 1:
3.DataScience Machine learning – Decision Trees Algorithm
- Use Case: Missed application areas for decision trees include both classification and continuous variable prediction problems (such as customer churn or stock price prediction).
- Concept: A decision tree divides the features of the data into branches where each branch contains a test and each end of the branch contains an output. It is used to choose the features which are most appropriate to split the data and this can be with the help of other measures such as Gini index for classification,Mean square error for regression.
4. DataScience Machine learning – Random Forest Algorithm
- Use Case: Recommended system and systems where risk is estimated (as a function of a given input) among other jobs such as classification.
- Concept: Random Forest is an integration of multiple decision trees through the consolidation of the result from all the trees to provide a better and consistent estimation. Every tree in the forest is learnt from a random sample of the data and all the features and the final decision is often the mean of all the trees (for regression), or the mode (for classification).
5. DataScience Machine learning –Support Vector Machines (SVM) Algorithm
- Use Case: Most of the classification tasks and particularly binary classification in nature cover areas like: image recognition, bioinformatics etc.
- Concept The introductory purpose of SVM is to determine a hyperplane that’s in a maximum distance from data points belonging to different classes in a point space. The end is to have as important gap between the data points of the two classes as possible. SVM also has additional ways of processing nonlinearily separable classes by so-called kernel tricks.
6. DataScience Machine learning – K-Nearest Neighbors (KNN) Algorithm
- Use Case: Decision Tree works well in both classification and regression problems or applications such as recommendation engines and pattern managers.
- Concept: KNN makes classification given that the classes assigned to the sample to be classified are similar to its neighbors. In bracket problems the maturity class from among the knn nearest neighbors is the class assigned. For retrogression, the affair is the normal of the values of the nearest neighbors.
7. Machine learning – Naïve Bayes Algorithm– DataScience
- Use Case: classification problems generally and especially in text classification problems such as spam detection, sentiment analysis.
- Concept: Naïve Bayes is founded on Bayes’ Theorem, probability of an event given preceding conditions of an event.. The “naïve” part so called because this model assumes that all the features of a given dataset are unrelated, making the computations easier.
8. DataScience Machine learning – Gradient Boosting Machines (GBM) Algorithm
- Use Case: Classification problems (identification of fraudulent credit card transactions, credit risk scoring), as well as regression problems (estimation of customers’ response rates to promotional campaigns).
- Concept: While in Gradient Boosting, it is a procedure to create a group of multiple weak models; most often, decision trees are used, and the base models are separate correction of the previous model’s errors. intuitive and other two include XGBoost and LightGBM which are reputed for their efficiency and many-task performance.
9. Neural Networks
- Use Case: For high-dimensional data types such as images, audio and text as well as for tasks which are time-consuming, like image classification, speech recognition.
- Concept: Although it is a kind of neural network, it also includes “neurons” which connect one to another to form layers. Each neuron takes the data goes through some operation of the data and passes onto the next next layer. By this, the network gradually tuning the weights in a way such that it reduces the amount of error in its predictions.
10. DataScience Linear Discriminant Analysis (LDA)
- Use Case: Classification jobs (such as face identification, customer profiling).
- Concept: LDA is for finding a transform that best produces a linear space between two or more classes of features. No assumption is made about the shape of the distribution of the data within each class and covariance is also assumed to be the same for all the classes.
Machine learning Supervised Learning Steps:
- Data Collection: Gather labeled data.
- Data Preprocessing: Handle the null or the missing values, and also select / engineer the features or the variables.
- Splitting the Data: Randomly divide the data base into a training set and a test data.
- Model Training: Create using the training set only a model.
- Model Evaluation: Using the test set reduce the over fitting of the model until the prediction of test data generates high values of accuracy if it is classification problem or low MSD if it is regression problem.
- Model Tuning: Tune the hyperparameters so as to device a better performance of the systems.
- Prediction: Employ the model learnt to forecast results of unseen data.
DataScience Machine learning algorithms are applied in many fields and
post industries post office and post sectors to find solutions to real problems with the help of data and make predictions or choices. Below are some common applications of machine learning algorithms:
1. DataScience-Healthcare
- Medical Diagnosis: Diagnostic models (logistic regression, decision trees or neural networks) are applied to diagnose diseases, including cancer, diabetes, or heart diseases based on patient’s data: symptoms, medical information, and lab results.
- Drug Discovery: Big data techniques such as random forests as well as neural networks can screen possible drug compounds by dissecting chemical frameworks then estimating their biological consequences.
- Personalized Medicine: Treatment suggestions that are based on patients’ genetic profile and medical records are given with the help of models.
- Medical Imaging: Cancer detection; tumour detection, fracture detection or any other abnormalities in MRI scans, X-rays and CT scans are performed using Convolutional Neural Networks (CNNs).
2. DataScience-Finance
- Fraud Detection: While the transactions occur, random forests, gradient boosting and similar machine learning models are able to identify fraudulent transactions in the transactions data.
- Credit Scoring: Calibrations and probabilities of logistic regression and support vector machines (SVM) are employed to identify credit risk by estimating the risk of defaulting that is represented by income, credit and financial disposition.
- Algorithmic Trading: The two popular approaches are reinforcement learning together with deep learning choosing managements in the stock markets.
- Risk Management: Valuation models are utilized to identify credit worthiness through data analysis to estimate future risks of an investment or loan.
3. Temperature and humidity monitoring in Retail and E-commerce through DataScience

- Product Recommendations: Recommendation techniques like collaborative filtering and content-based filtering where algorithm involve KNN, matrix factorization and even deep learning suggest customers to go for which product that they are likely to love.
- Dynamic Pricing: Based on demand, stock availability, competition and other parameters, real-time price control and machine learning algorithms together with regression models affect the best pricing strategy.
- • Customer Segmentation: Sales promotions, for example, by using K-means or hierarchical clustering, classify customers into unique categories that enable selling companies to target the specific category more efficiently.
- Inventory Management: ML is duly capable of predicting the demand levels of a specific product and balance the inventory to avoid ballooning of stock, or lack of stock.
4. DataScience-Marketing
- Customer Lifetime Value Prediction: Regression and decision trees are used today to forecast how much a particular customer will spend in the course of a life time, hence offering marketing strategies to only target customers who have a high lifetime value.
- Churn Prediction: Customer churn is determined through logistic regression, random forest or gradient boost machines to affect tailored retention strategies.
- Ad Targeting: Programmatic buying applies the machine learning algorithms and offers the advertising content in accordance with the target audience’s Web surfing and purchasing activities.
- Sentiment Analysis: Machine learning techniques such as Naive Bayes, Support Vector Machine (SVM) or recurrent neural networks (RNN) work through the customer reviews, social media tangible feedbacks about the products and services offered.
5. DataScience-Manufacturing
- Predictive Maintenance: Integrated sensors collect data from machines to define when the equipment is likely to break down, thereby minimizing time losses and unnecessary repairs.
- Quality Control: Image recognition algorithms are as simple as CNN and can be utilized to detect defects in products through images from assembly lines.
- Supply Chain Optimization: Set of algorithms such as reinforcement learning or optimization models may enhance the value-driving networks where routes or inventory or logistics are determinative.
6. It’s thus fitting that we’ve seen a focus on data science in cities and in transportation and autonomous systems.
- Autonomous Vehicles: Self driven cars employs certain type of machine learning known as deep learning like CNNs and RNNs for object detection, lane detection and decision making for actions using sensors and cameras.
- Route Optimization: Dijkstra’s algorithm, reinforcement learning, KNN, selects the quickest and fuel efficient delivery routes.
- Demand Prediction for Ridesharing: Ride-sharing companies employ regression, time series analysis models to forecast demands in certain geolocations and create availability and charges to reflect this.
7. Data Science is one of the most trending things in the technical world and Natural Language Processing (NLP) is one of the sub-topic of it.
- Speech Recognition: About speech recognition for virtual assistant such as Alexa or Google Assistant, the state of arts deep learning models includes RNNs or transformers is employed.
- Text Classification: Features that used in Naive Bayes, SVMs, or deep learning are used to sort an email as a spam or not spam, or documents into categories.
- Machine Translation: Science and technology apply sequence to sequence such as GPT, BERT for activities like automatic language translation for instance translating an English text into Spanish.
8. Energy
- Energy Consumption Prediction: Forecasting models used to predict the energy demand in the future assist the utility firms to balance supply to limit wastage.
- Smart Grids: Smart meters enable collecting of various data from houses and smart grids and machine learning algorithms can be used to improve electricity distribution.
- Renewable Energy Forecasting: Neural networks and regression models are used for the forecast of energy generation from wind power or solar power depending on the meteorological data.
9. Security
- Intrusion Detection: Artificial neural networks like SVM, k-nearest neighbor, and deep learning in general identify a cyber-attack or intrusion when the system outlines an anomalous traffic pattern.
- Facial Recognition: CNNs are employed to augment surveillance and security systems because they are able to recognize people within frames or a continuous flow of real-time footage.
- Spam Filtering: Naive Bayes and other classifiers, as related tools, sort out spam emails comparing them with previously classified emails in terms of their content and metadata as well as user’s interactions with them.
10. Entertainment
- Content Recommendations: The Netflix and YouTube, two of the most popular streaming services make good use of both the collaborative filtering model and the deep learning models to suggest films, TV programs or videos to subscribers according to their preferences.
- Game AI: Reinforcement learning is usually applied in designing self-acting entities for video games which learn policies and actions from one game.
- Music Generation: Some of these models are generative in that they are used to generate new music or art in the same style as the input music or art for any of the following generative models : GANs, RNNs.
11. Agriculture
- Crop Yield Prediction: There are machine learning algorithms in practice today (Regression models, Decision trees) that forecast crop yields depending on soil characteristics, climate and kind of crop.
- Pest and Disease Detection: The computer vision potentials include image recognition algorithms, usually applied on the basis of deep learning, which can classify diseases or pests on images of crops.
- Precision Farming: Precision agriculture is applying machine learning to analyze data generated from the machinery in the field such as the sensors, drones, and satellites so as to determine the right time to plant, fertilize, and water.
12. Human Resources
- Resume Screening: Through screening resumes, the conventional techniques can be replaced with a machine learning application; that identify and match qualifications, skills and experience with the job description’s detail.
- Employee Attrition Prediction: A type of machine learning is employed to estimate employees’ turnover based on the indexes of job satisfaction and performance as well as organizational characteristics.
- Performance Evaluation: Forecasting techniques can also be utilized to understand current and past data concerning employee performance and assist managers with performance appraisals and activities for staff improvement.
Here we discuss some of the numerous ways in which various machine learning algorithms are employed in various applications. The application of the machine learning will extend with the advancement of technology and more areas of business will be served by machine learning.
Artificial Intelligence Big data Analytics challenges of Machine learning-
Let’s consider the foresaid example about how machine learning (ML) can impact several fields and industries and know that it is not without drawbacks. Below are some key drawbacks of machine learning:
1. DataScience Data Dependency
- High-Quality Data Requirement: The successful implementation of ML models depend on the availability of voluminous good quality data for training. In many situations, such data can be expensive to gather and store, time consuming, or simply out right hard to obtain.
- Garbage In, Garbage Out: If the input data is contain much noise, bias or if some features are missing, the result of the model will be wrong. This may result in the creation of models with poor quality data which do not hold when applied in real world scenarios.
2. DataScience Overfitting and Underfitting
- Overfitting: If a model is overly complex, then it assumes the random variations in the training data as the regularities. It leads to weak result on unseen test data since the discriminant function does not generalize.
- Underfitting: If a model is simplistic it merely provides an incorrect representation of the true regression effect within the data and the error is seen both when training and testing.
3. DataScience -Black Box Nature
- Lack of Interpretability: Most of them especially high-level ones such as the Deep Neural Networks, have been referred to as ‘Black boxes.’ They might work well in situations where decision-making is required, however, it is not always clear how they come up with a specific decision, or a prediction for that matter, which can be troublesome in sensitive and especially critical areas such as healthcare, finance or law.
- Trust Issues: Some of the ML models may be rather black box, meaning that people can only input data and get out the results, but cannot know why a certain result was arrived at, which is a problem in some sensitive areas like medicine.
4. DataScience-Bias and Fairness

- Algorithmic Bias: ML models are not immune to original bias and in fact may reinforce the bias at higher levels than in training data. For instance, Bias in the data set might make hiring decisions, lending, or even police and criminal justice decisions’ unfair to a specific category of the population.
- Ethical Concerns: These are issues of bias the continuation of which raises ethical questions; more so where the model is applied in areas such as criminal justice, health care or employment where issues to do with fairness and equality are of particular concern. Said algorithms can cause self-serving and unsafe results or perpetuate injustices.
5. Data Privacy Concerns
- Privacy Violations: Many ML models depend on the amount of data, sometimes the data contains some privacy information/ data. This is a big issue on data sovereignty especially now that companies all over the world are facing regulatory bodies such as GDPR from the EU, or CCPA from California.
- Model Inversion Attacks: Sometimes, the attackers can extract vital details from the training database, which is quite a privacy vulnerability despite trainable and predictable nature.
6. High Computational Costs
- Expensive Hardware: Training complex models, especially those characterized by the deployment of deep learning algorithms, calls for powerful GPUs as well as some specialized hardware, among which TPUs are dominant. These can be very expensive to purchase and use or even only expensive partly.
- Energy Consumption: Using larger scale complex networks especially those that employ Deep learning consume a lot of energy and therefore attracts high energy costs environmental footprint.
- Long Training Times: There are still limitations to how quickly we can train large models on huge datasets can take, hours, days or even weeks depending on the problem’s complexity and resources.
7. Difficulty in Generalization
- Out-of-Sample Generalization: Supervised ML models, in particular, are designed to find the relationship between the input data and the output data used during the training period that is why they can perform poorly if the input data differs from the training data. For instance, a model which has been derived with objectives of recognizing objects in existence in sunny conditions will not perform well in foggy conditions.
- Domain Adaptation: Domain adaptation of a model built for one type of application (such as, recognizing cats and dogs) over another type of application such as medical imaging would require time and some level of reinforcement.
8. Need for Expertise
- Complexity of Models: Training the models also involves understanding and application of statistics, algorithms and program languages leading to model construction. Not all organisations have the resources to implement, train and maintain machine learning systems properly.
- Hyperparameter Tuning: Several ML models are known to be highly sensitive to a number of hyperparameters (e.g., learning rate, the size of the regularization term). Sometimes it may involve a lot of time and may require very many trials to come up with a final result that will be desirable and workable.
9. Security Vulnerabilities
- Adversarial Attacks: The following is a review in which it is pointed out that, as is the case with other techniques, ML models remain prone to adversarial attacks, which affect the input data, and are able to cause radical changes in the results of the models. For instance, the alteration of small pixels embedded in a picture can provide the classifier with wrong information.
- Model Poisoning: The bias can also be achieved when the attackers decide to feed the training set with wrong data that leads to development of compromised models that make biased or wrong decisions.
10. Difficulties of Feature Engineering
- Manual Feature Extraction: In many traditional ML applications, feature engineering, how feature variables are selected and transformed, is an important step. This is usually very time consuming and usually needs additional specialized knowledge about the specific domain.
- Curse of Dimensionality: Large datasets can be problematic for some algorithms, and with high-dimensional data, it becomes more difficult for the model to find something of interest. Pattern without overfitting.
11. Scalability Issues
- Limited Scalability: Most of usual machine learning algorithms face problems related to scalability when operating on huge amount of data or in distributed systems. Further, if the data size is large, a number of traditional Machine Learning algorithms such as SVM or decision trees may fall short in terms of performance when scaled up, on the same data.
- Real-Time Processing: A number of ML models struggle to handle real time data or process streaming data at high velocity whereas these are designed to handle batch data.
12. Changing Data (Concept Drift)
- Dynamic Environments: In many real-world applications the data evolves or shifts in some way (e.g. users’ actions, stock exchange). This was described as ‘concept drift’ can reduce the effectiveness of an intermediate allocated ML model if not refresher or retrained.
- Retraining Requirement: They need to be retrained when the data distribution on which they are based alters hence it can be very expensive and time consuming.
13. Lack of Causal Understanding
- Correlation vs. Causation: Algorithms which make use of ML can find patterns within data, however, they are incapable in understanding causality. That is why this can lead to clearly erroneous conclusions, especially in such disciplines as medicine and the economic and social sciences where the identification of cause-and-effect relationships is of paramount importance.
- Dependence on Historical Data: There are several issues in using ML models, for they can only improve on whatever information has been presented at one point, and thus may not be able to pick up new trends that have however not been seen in the past.
14. Maintenance and Updates
- Model Degradation: Unfortunately, the accuracy of ML models /forecasters may decrease as a function of time due to new phenomenon in the data or the data changes. Frequently, the program will require the update or re-training of performance levels.
- Monitoring: After the models are deployed the continuous monitoring must be done to guarantee that it is working perfectly, it is making correct predictions, and it is not straying away in accuracy.
15. Ethical Implications
- Job Displacement: The deployment of automation through instance learning could make existent careers redundant hence sparking debates regarding the social economical effects of implementing instance learning.
- Decision-Making Responsibility: When decisions are made decided by algorithms, then the question of who is responsible for these decisions is raised. For instance, who is to blame when an autonomous vehicle kills people or when an algorithm that is developed is prejudiced and discriminates people?
Summary:
However, machine learning has the potential to solve a wide variety of problems and these barriers must be dealt with so that the importance of the ML systems is realized. These include quality control of input data, control of potential sources of bias, increased model interpretability and key societal issues such as ethics and privacy.
1 thought on “DataScience – 10 Machine Learning Algorithms”