Decision Tree -Mathematical intuition Must to know for below
1.Entropy–(To check the purity of the node)
2.Gini Impurity (To determine the purity of the node)
3.Information Gain (determining which feature to select for decision)
4. Post Pruning.
5. Pre pruning.
6.Entropy Vs Gini Impurity..(which is fast)
Decision Tree is a popular supervised machine learning algorithm used for both classification and regression tasks.It divides data into subsets depending on feature values, creating a tree structure with each internal node representing a feature (attribute), each branch representing a decision rule, and each and each leaf node represents the output (class label for classification or a continuous value for regression). Decision trees are simple to understand and perform well with both categorical and continuous data.
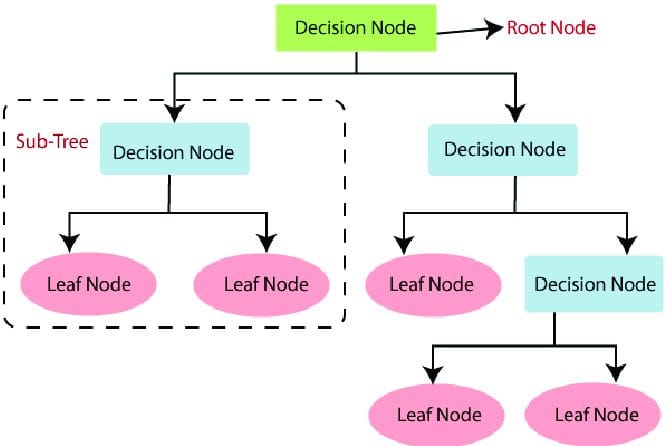
Key Concepts of Decision Trees:
Structure of a Decision Tree:
- Key Concepts of Decision Trees: Key Concepts of Decision Trees:
- Structure of a Decision Tree: Structure of a Decision Tree:
- Root Node: It is the view of the whole dataset and the basis of learning. It divides the data in multiple subsets according to the most informative feature or the one which is most adulterated.
- Internal Nodes: Every internal node is a feature and progressively determine the decision about splitting the data further or not given some conditions/thresholds.
- Branches: More precisely, to record the decision result in an internal node.
- Leaf Nodes represent the final prediction. In classification trees, each leaf node is a class label and, in regression trees, each leaf node is a continuous variable.
- Splitting criteria: Splitting criteria:
- The Decision Trees technique recursively separates data by choosing attributes and thresholds that iteratively reduce impurity or enhance information gain, respectively, at each node. It is also possible, when tackling a specific task, to use an alternative splitting criteria.
- Classification Trees: Classification Trees:
- Gini Impurity: Measures the probability that a randomly chosen element would be incorrectly classified if it was randomly labeled according to the distribution of labels in the subset. The Gini Impurity is given by: [
Gini = 1 – \sum_{i=1}^{c} p_i^2
] where ( p_i ) is the probability of selecting a class ( i ), and ( c ) is the number of classes. - Entropy and Information Gain: Entropy measures the disorder or randomness in the data, while Information Gain quantifies the reduction in entropy after splitting the dataset based on a feature.
- Entropy is defined as [Entropy(S) = – \sum_{i=1}^{c} p_i \log_2(p_i)]. (p_i) represents the proportion of examples in class (i).
- Information Gain refers to the reduction in entropy after splitting. [Information Gain = Entropy(parent) – \sum (\frac{|child|}{|parent|} \times Entropy(child) \right)].
- Gini Impurity: Measures the probability that a randomly chosen element would be incorrectly classified if it was randomly labeled according to the distribution of labels in the subset. The Gini Impurity is given by: [
- Gini Impurity: Gives a numerical estimate of the probability (under random labeling), of an element being falsely labeled, if random labeled from the labelling distribution in the subset. The Gini Impurity is given by: [
- Gini = 1 – \sum{i=1}^{c} pi^2
- The ability of the selection i.e., “class i”, “class c” is the number of classes.
- Entropy and Information Gain: Entropy measures the degree of disorder or randomness in a data set, and Information Gain measures the degree of ordering that can be saved by partitioning a data set based on a feature.
- Entropy is defined as [Entropy(S) – \sum{i=1}{c} pi \log2(pi). (p_i) represents the proportion of examples in class (i).
- Information Gain is characterized as entropy reduction following division. [Information Gain Entropy(parent) – \sum |child||parent| \times Entropy(child) .
- Regression Trees: Regression Trees:
- Mean Squared Error (MSE) calculates the error between predicted and actual values, less the variance within clusters.
- Mean Absolute Error (MAE) is a metric of the absolute difference between the fitted and surrogate values and it has been applied to regression trees.
- The Mean Squared Error (MSE) measures the difference between expected and actual values, reducing volatility within groupings.
- Mean Absolute Error (MAE) is a measure of the absolute difference between predicted and actual values, commonly used in regression trees.
Building a Decision Tree: Building a Decision Tree:
For the build up of a decision tree the data set is recursively split in the different parts, of which the feature that minimizes reduces the impurity (classification) or the variance (regression), respectively.
Choose the Best Feature to Split: By leveraging the capability of each feature in terms of impurity (Gini/entropy) or variance (MSE/MAE) reduction and the feature with the highest score, the process of classification is established.
Split the Data: According to the chosen features, the data is divided into subsamples.
Repeat the Process: For each subset, the procedure is done recursively in an iterative way, leaving one of the relevant good features and recursively splitting it, producing a tree structure.
Stopping Criteria: The process is iterated until a of the stopping criteria is obtained: .
For all samples on the node, samples are of the same class (pure node).
The maximum tree depth is reached.
A minimum number of samples per node is reached.
No further gain in splitting can be achieved.
Pruning the Tree: Pruning the Tree:
Decision trees can get quite deep, resulting in overfitting. For instance, so as to avoid it, the tree is pruned to reduce the complexity of the tree.
Pre-pruning (early stopping): Keep the tree at each level not prematurely (e.g., by stopping at the tree with the maximum depth, the number of samples per leaf, etc. ).
Post-pruning: Examples where the entire tree is sprouted and then pruned to remove irrelevant branches that are not informative or result in overfitting.
Example of Decision Tree Algorithm (Classification): Example of Decision Tree Algorithm (Classification):
Suppose we have a dataset to predict whether a consumer will buy the product (i.e., a decision), given his/her age, an income, and whether or not is owning a car.
Root Node Selection: Root Node Selection:
Since the beginning of the procedure, the algorithm calculates the Gini impurity (or entropy) of the variable (age, income, car ownership) and chooses the variable that yields the highest information gain (or the lowest impurity, e.g., age).
Splitting the Data: Splitting the Data:
If a target feature (e.g., age) is selected, the data are divided into different subsamples (e.g., age 30, age 30 age 50, age 50).
Recursive Splitting: Recursive Splitting:
For any of those subsets such a local step is recursively performed, selecting the next best feature (e.g., income, car ownership) and splitting it into further subsets.

Final Prediction: Final Prediction:
At the base of each tree, the algorithm infers that there is an label in the most dominant leaf child (e.g., “Buy” or “Not Buy”.
Advantages of DT
Easy to Understand and Interpret: Decision trees are tractable both to understand and to see so they are particularly useful for tasks concerned with decision making.
No Need for Feature Scaling: In contrast to algorithms, e.g., KNN or SVM, decision trees can always be trained in the absence of the use of feature normalization or standardization.
Decision trees can work with mixed data types.
Non-parametric Model: Decision trees do not hypothesis on the data distribution of data that they are being provided.
Decision trees are capable of modelling complex non-linear, non-linear functions between features and the target variable.
Disadvantages of Decision Trees: Disadvantages of Decision Trees:
Overfitting: Decision trees are also very much scandalized for overfitting, particularly when the tree is complex and deep.
Instability: Substantial differences in the data can lead to entirely different trees because of the tree nature of the splits.
Bias Toward Dominant Features: Decision trees are also known to be sensitive to features with more than one level (i.e., continuous variables, not categorical variables, with only a limited number of categories).
Not the Best for Regression Tasks: Regression decision trees may produce discrete level estimates and hence produce spikey predictions and suffer reduced performance from other methods (e.g., linear regression or random forest.
Improvements Over DT: Improvements Over DT:
Random Forests: Random Forests:
Random Forest is an ensemble of decision trees to improve prediction accuracy and to avoid, particularly due to overfitting, . It constructs \emph{a family} of decision trees, and each tree is trained \emph{at random} on both the data and features. The final prediction is derived by averaging (regression) or majority voting (classification).
Gradient Boosting Machines (GBM): Gradient Boosting Machines (GBM):
Gradient Boosting is another ensemble method, in which decision trees are trained in order of increasing depth, such that each tree corrects the residuals of the errors of the preceding one(s). The model learned in phases to minimize error (residuals) progressively leading to high prediction performance.
XGBoost and LightGBM: XGBoost and LightGBM:
State of the art implementations of boosting algorithms based on decision trees as weak learners. They are based on speed and efficiency, and they show state-of-the-art results on a large collection of real-world tasks.
Applications of DT
Customer Segmentation: Decision trees are applied (e.g., for customers’ classfication/segmentation) not only in relation to the behavior pattern of customers but also in relation to demographic characteristics.
Fraud Detection: Decision trees may also be applied to fraud detection systems for the purpose of detecting patterns of fraudulent behaviour.
Medical Diagnosis: Decision trees have been widely used applications in medical fields for providing a diagnosis on the basis of patient information (e.g., age, symptom, test).4).
Credit Risk Assessment: At banks and financial institutions, decision trees are used to make risk estimates for decisions about extending loans to borrowers of interest.
What Are Decision Trees in Machine Learning?
Decision tree is a supervised learning method used for comparative analysis and prediction. The strength in this aspect lies in recursively splitting data into sub-data, while simultaneously training its tree-like model. Decision tree, in a nutshell, is defined as a collection of nodes containing attributes, decision nodes and leaf nodes nodes.
Decision trees are therefore promising approaches to tackle the challenging problems due to simple process nature. Compared with the other algorithms, decision trees, actually a model that is clear and easy to understand, of decision making, it is easy to visualise and thus can be presented.
How Decision Trees Work: The Splitting Mechanism

Decision tree strength lies in its data slicing. For each node, this algorithm chooses an RS (criterion attribute) that can efficiently partition the data in different clusters. The split criterion can either depend on the classification task or on the regression task.
In classification problems the metrics Gini Impurity or Entropy (partitioning the problem with Information Gain) exert the decision roll over the splits. Mean squared error (MSE) minimization is an established objective in regression problems. The tree continues to grow until a limit (the depth, the number of samples per leaf) is reached in its network.
Advantages of Decision Trees in Machine Learning
DT stand out due to their remarkable interpretability. In comparison to the computationally intractable neural network, the decision rationale of dtmodel decision making is clearly visible and interpretable, and is especially useful for any industry demanding transparency.
Moreover, dt require minimal data preprocessing. They are resistant to outliers, data with both categorical/numerical modalities do not require special treatment, and missing data are not a sensitivity. Non-parametric, in principle, they are designed to be such, because they are based on an assumption as to the distribution of the data, “and on this basis can very easily be made to handle large data” (they claim).
Challenges in Using Decision Trees
DT, though general, are not without limitations. With an increasing number of splits the model will ultimately come to increasingly model noise, rather than pattern. As a countermeasure to this, pruning techniques or weight pruning, e.g., maximum depth, allow.
Another challenge lies in their instability. Slight variations of the data can cause relatively large variation in the structure of the tree. Such sensitivities can be tuned, through use of ensemble methods (i.e., Random Forests or Gradient Boosted Trees) by averaging the trees of the ensemble.
Real-World Applications of Decision Trees
DT are also much used in industry due to their generalization and interpretability. They are also employed in the medical field for disease diagnosis, by gathering the patients’ symptom and medical history information. DT have also been applied to credit risk modeling and spotting fraudulent transactions for finance.
In particular, decision trees are especially suitable to the customer segmentation and behavior prediction for marketing. From the point of view of companies, it is possible to modify their planning in such a way to allow them to reach some consumer segments in a more efficient way (i.e., determined by purchase pattern and demography). Decision trees are applied for learning purposes in the same manner as for predicting student success/failure and determining the dimensions for both student success/failure (e.g., linear, nonlinear).
Enhancing Decision Trees with Ensemble Methods
DT are now quite powerful in their own right and can likely also be made even better by use of the ensemble technique. Ensemble learning of a large number of decision trees is applied to build the Random Forest to the advantage of less overfitting and better generalization. It is learnt by training each tree with a random draw of the data set, the training dataset, and averaging the resulting prediction.
Next, those who move from simple (e.g., Gradient Boosting or AdaBoost) basic ensembles to (steps) sequential (sequences) trees. Each tree is trained to compensate for the mistake of the previous tree and the final model is, as a result, very robust. These methods constitute a very attractive compromise between interpretability and performance, interesting in both the scope of machine learning competition and deployment.
Best Practices for Implementing Decision Trees
However, for the full potentiality of decision trees they should be approached according to some special rules of thumb in order to optimize their performance. Begin by understanding your dataset thoroughly. Data cleaning and missing data imputation can be very useful in the performance of trees. Although they work to the categorical data, encoding (e.g., one-hot encoding) can still help improve the performance.
Setting hyperparameters is crucial. Complexity (set of parameters, e.g., maximum depth, number of samples per split or minimum samples for the leaf) of the tree is determined by parameters. Proper tuning can help balance underfitting and overfitting. However, cross-validation guarantees that the tree is sufficiently generalizable and has learned sufficiently for new data.
Finally, consider interpretability versus accuracy. Although ensemble method can bring a positive gain that can directly improve performance, it will always come at the cost of its interpretability. Select an answer that fits within the scope of your project and the needs of your stakeholders.
The Future of Decision Trees in Machine Learning
Decision trees are the offspring of a nearly primitive algorithm, as the field of machine learning (ML) searches for new horizons. Due to their simplicity, seethoreness, and generality, there is rationale to see to expect that these approaches would see much wider interest with regard to their potential for applicability to classical and modern applications. Due to the evolution of ensemble learning and hybrid solutions, decision trees are gaining popularity, and have already been integrated into architectures (e.g., deep learning and artificial intelligence).
Scalability of decision tree builders has also been investigated for big data [2]. Using distributed computing and parallelization, decision trees can be applied to big data in a computationally feasible way. Decision trees are ideally positioned to help bridge the gap between. Ubiquitous black boxes and human intuition in a world where there is a growing demand for explainable artificial intelligence (AI).
Conclusion:
The decision tree (dt) approach is an effective, interpretable classification and regression machine learning algorithm. It is the foundation of several effective ensemble algorithms including Random Forests and Gradient Boosting. Although decision trees are known to suffer from overfitting and to be unstable (i.e. (two, including uncertainty), decision tree is also useful for inference and the interpretation of decision learning process). into the relationships between features.