Ensemble Techniques-Uses:- Ensemble methods are techniques that create multiple models and then combine them to produce improved results. Ensemble methods produces more accurate solutions.
Below Techniques must to know to build best prediction Model:-
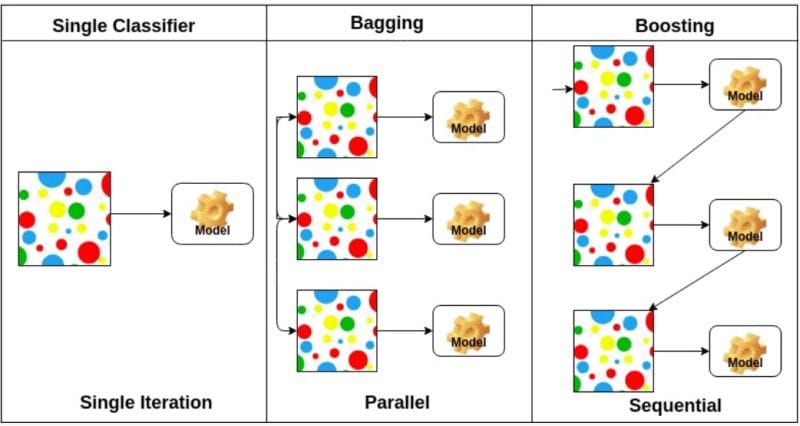
1.Bagging: Parallel model approach ,Take majority voting predictions to give best results.
–>Random Forest
2.Boosting: Sequential Model approach ,build stronger classifier from many weaker classifiers .
–>Ada Boost
—>XG Boost
Ensemble Techniques in Machine Learning
Ensemble techniques are powerful machine learning methods that combine predictions from multiple models to improve accuracy, robustness, and generalization. The primary idea behind ensemble learning is that by aggregating the outputs of several models, the ensemble can compensate for the weaknesses of individual models and reduce the risk of overfitting, leading too more accurate and reliable predictions.
A Deep Dive into Ensemble Techniques in Machine Learning
Machine learning changed the paradigm of problem solving, e.g., from predicting human behavior of customers to disease treatment. Ensemble methods are at the forefront of its powerful tools as a high performant and easy to use solution to obtaining high accuracy and robustness. The techniques employed are based on the combination of multiple single models in order to obtain an optimal predictive model. The ensemble method has been the tool of the trade across the competitive data science field and has been employed for multiple challenges.
This paper discusses the details of ensemble methods in machine learning, providing a systematic description of the categories, how class is effected, advantages, disadvantages, and concrete use cases. By artistically combining related keywords it is a tool for gaining expertise for anyone who wants to become an expert in this basic application field of machine learning.
What Are Ensemble Techniques in Machine Learning?
Ensemble methods consist on the aggregation of several learning functions in one robust model. The principle is that a set of feeble learners, models with a small degree of prediction advantage over random guessing, can be aggregated into a robust learner with much stronger predictive performance.
Ensemble Techniques-This concept mirrors decision-making in human contexts. For instance, in a jury, individual and individual preferences for a and b might be prejudiced against a and b, respectively, but when a group of people come together they can make a biased decision a and a biased decision at the same time that is also fairer. In particular, by calculating the mean, the solutions from single models suffer from bias, variance and underlying errors in single models.
Ensemble Techniques-The strength of ensemble methods then originates in the potential to combine several inductive building blocks,e.g., no overfitting, no noise mitigation and finally omnibus pattern generation. In this case, if single models do not meet the accuracy to fulfil the high accuracy, etc, and the method becomes unstable, etc, the method is quite promising in practice.
Types of Ensemble Techniques in Machine Learning
Ensemble Techniques-Bagging and boosting, respectively, by mechanisms and functions. Bagging (bootstrap aggregating) is a method of reduction of variance fitting models to independent data subsets, i.e., bootstrap samples of the data. Conversely, boosting tries to reduce this bias by repeatedly training models, with the error of the previous model being corrected in each update.
The result is definitive by merging the results (a majority vote as in classification and an average vote, respectively, when combined with a regression task).
Boltzmann Boosting (BB) and AdaBoost are recursive or stepwise. In cases of such techniques, previously erroneous data has a significant impact on the learning and the model is trained using hard features directly embedded in the patterns. Iterative learning of advantages of cascade structures, which is represented by boosting, gives rise to an extremely powerful (efficient) ensemble model.
One of the highest-relevants techniques is stacking, in which a single or multiple base models outputs are used as input of a meta-model. This meta-model is trained with desirable properties for an effective combination of the outputs of the underlying models and thus this meta-model remains a powerful, high-level, general-purpose ensemble.
The Science Behind Ensemble Techniques
Ensemble Techniques-The performance of ensemble is grounded in the concept of diversity. When the ensemble performs better than each of the base learners, the base learners should have low correlation with the errors. Because of this multimodality, while one model may “lose” portion of the data, then another one will “gain” the erroneous portion.
Bagging makes each model heterogeneous in that it is trained on a unique, random sample of the data (with replacement). Compared, however, the extra mass of optimizing not only induces diversity by giving different weight to training samples, but also by allowing this weight to be given more and more liberally to training samples which models have previously been unable to learn properly.
Another critical factor is aggregation. Aggregating (i.e., calculate mode, average, voting) using bagging, is simple, i.e., calculating the average or voting. Boosting is a weighted average of the models used in the final prediction, where heavier weight is given to the more robust models. The meta-model is used to choose the optimal integrated model among the base models, and to make use of the complementary information within the top-level models.
Ensemble methods also take advantage of the bias-variance tradeoff. Averaging variability differences to decrease variability produces a more parsimonious variance model, which is statistically more robust, and in general, generalizable. Boosting, however, can also mitigate the bias of a continuous learning process to provide a data driven model representation of the data, such that a rich pattern can be learned.
Advantages of Ensemble Techniques in Machine Learning -Ensemble Techniques
Ensemble Techniques-The strength of ensemble methods is due to their good predictive performance. A family of models can be established through pooling, improvement and further stabilization of models at individual level. This is why they are suitable for solving complex problems of a high stakes nature, for example, medical or financial forecasthing.
Ensemble techniques also excel in handling noisy datasets. While all individual models suffer from the issue of noise overfitting, noise can be suppressed in an ensemble by averaging noise which leads to more reliable (i.e., robust) prediction. This property is particularly valuable for in-the-wild use, when abundant data is noisy and sporadic.
Another strength of ensembles is their versatility. These also can serve as input to teach a base learner by various methods, e.g., decision tree/neural network, support vector machine, etc. This portability enables practitioners to implement the ensembles in their data and tasks.
Furthermore, with regard to the issue that models are not always trustworthy, the solution is ensembles. However, the orchestration of single model outputs, such as Random Forest ensembles, yields more confident and a typical appearance. There is a practical importance to such stability with regard to problems in which reproducibility is needed.
Challenges in Implementing Ensemble Techniques
Ensemble Techniques-One of the most significant is computational complexity. Increasing number of the models can be also perceived (both in terms of the required computing capacity as well as in terms of the available memory) similarly to Random Forest or Gradient Boosting.
Another challenge is interpretability. However, because of single model’s natural interpretability, decision tree, ensembles are a black box. Information omission, as in the case above, may serve as a social negative in beneficiaries area, especially when the reasons of the beneficiaries are crucial, e.g., the medical and financial.

Overfitting is another potential issue, especially in boosting methods. Because boosting models are trained by hard examples/very hard examples and misclassified examples, boosting models are very prone to overfitting in the presence of data in noise. Carefully selected hyperparameters (ie, learning rate and the amount of iterations) are crucial so as not to incur this risk.
Base models and aggregation methods, however, still require careful selection in ensemble methods. And the aggregation function itself has to make a tradeoff between exploitation of local benefit and global generalization.
Applications of Ensemble Techniques in Machine Learning -Ensemble Techniques
Ensemble learning is a very effective way to obtain robustness and accuracy on a large number of applications. Ensembles are used in all disease diagnosis (i.e., diseases for medical applications) applications, patient response prediction applications, and personalized treatment planning applications. When model outputs are heavily involved in the construction of the final output, the ensembles move closer and closer to production of accurate and stable predictions.
Ensemble techniques are used for credit scoring (finances), fraud, and risk analysis. Their ability to apply noisy, imbalanced data, e.g., because of the nature of the ensemble, makes them a perfect candidate for such an application where the most important metrics are precision.
In the field of marketing, by using ensembles, customer segmentation and prediction of responsive behaviors and recommendations are possible. Ensembles detect clusters and patterns in the tremendous amount of customer data used as a foundation for targeted marketing campaigns.
In natural language processing, ensemble techniques can be used to improve sentiment analysis, language translation, and text classification tasks. Realized by a family of models (ensembles), the linguistic sophistication of human language is represented by ensembles, and, as a result, higher accurate and contextually appropriate predictions are achieved.
Best Practices for Building Ensemble Models -Ensemble Techniques
Ensemble Techniques-As far as the ensemble models are concerned, some of the good practices that can be taken by the practitioners already exist. Starting with a comparison of the advantages and disadvantages of the single base learners. Choose mixed models complementary with respect to each other and heterogeneous with respect to the rest to form the ensemble.
Data preprocessing is equally critical. However, the information that is being used for implementing the ensemble model is such that it will learn meaningful patterns, instead of meaningless ones. Its performance is further enhanced when missing values, outliers and imbalanced data are addressed.
Tuning hyperparameters is another key aspect. In bagging, the amount of base learners, maximum depth of trees are hyperparameters which influence the performance. Learning rate, number of iterations and regularization parameters are significant for boosting algorithms. To locate the suitable setting, grid search or random search is used.
Evaluate the ensemble using cross-validation to ensure generalization. Provide metrics (e.g., accuracy, precision, recall, F1 score) to make a comprehensive characterization of the system performance. Also for regression problems, one can also find a certain interest in such estimators, e.g. mean squared error (MSE) or mean absolute error (MAE).
Finally, balance performance and interpretability. While there is a tendency to claim in favor of accuracy as a proposal, it is also desirable to note that requirement for a given application is not necessarily the same. (At the cost of interpretatibility if needed)Use methods, e.g., feature importance analysis or partial dependence graph, to describe the behaviour of the ensemble.
The Future of Ensemble Techniques in Machine Learning -Ensemble Techniques
Ensemble methods also promising with their potential for scalability to high levels of complexity, generalization in the era of artificial intelligence. The history of deep learning trends is already giving an imprint on ensembles and deep ensembles, where neural networks are being used not only to enhance the accuracy, but also to improve the robustness.
Ensemble Techniques-Research is also focused on making ensembles more efficient. To reduce the computational burden of ensemble method, distributed computing techniques and compression model techniques have also been used to reduce the computational burden of ensemble method so that ensemble method can be used not only for solving large scale problems but also for resource limited problems.
Specifically, another major issue is to combine ensemble techniques with unsupervised/semi-supervised learning. Without any labeled data, ensembles can generalize their performance to scenarios in which labeled data is underspecified.
Because the popular trend of interpretable AI, ensembles are introduced for interpretability. Tools such as SHAP values and LIME have also been called ensemble predictions and therefore can be convincingly shown to stakeholders.
Expanding the Exploration of Ensemble Techniques in Machine Learning
Ensemble Techniques-In order to make a definitive statement on the potential and promise of ensemble methods in ML, it is necessary to consider the specifics, the practical effects and the fluid state of this developing paradigm. Ensemble methods are not just a basket of algorithms but rather a strategy for combining algorithmic strengths to create an ensemble output that is better than using an ensemble algorithm on the individual data. Based on this new information we attempt to disentangle the richness of ensemble schemes and the interpretability of ensembles within the machine learning paradigm.
The Philosophy Behind Ensemble Methods
diversity in perspective leads to better decision-making. However, there is no machine learning model that can learn the complete complexity of any given data set. Other algorithms are suitable for linear relations between data points, but for some other the relations are suitable for the data they analyse. For example, there are models that are resistant to the presence of outliers, and models resistant to noisy input.
Ensembles overcome these holes with a sense of collective identity. The focus is on the capacity of an ensemble to leverage the advantages of a group of models and to compensate for the weaknesses of a single model. The integration of the predictions of the individual models yields also robust and accurate ensemble predictions, which counterbalance the unavoidable error of the single models.
Exploring Advanced Ensemble Techniques
Ensemble Techniques-In addition to the traditional ensemble (bagging, boosting, and stacking) methods, a novel ensemble method is developed to overcome the limitations of ML. Two notable approaches are Bayesian model averaging and blending.
Bayesian model averaging introduces probabilistic reasoning into ensembles. In this scheme, although there is no a priori assumption that all models are equally good, they are separated from one another with respect to each other on the basis of a posteriori model weights, which are fixed on the basis of the relative fit of models to the data. This probabilistic weighting ensures that the ensemble uses the most effective models while keeping track of the membership of all the base learners.
Combination is also the synonym to composition, which is easy to be realized, but it only learns the meta-model from a single labelled holdout data set. Through training on unseen data, blend not only mitigates the issue of overtraining on training data and thus turns out to be an effective, practical, and potent substitute of stacking.
Another cutting-edge development is the use of hybrid ensembles. Hybrid ensembles are built from methods in an ensemble, i.e., from bagging methods by adding some method and from boosted methods where some method is included. The hybrid model is a relatively strong model, which can be applied effectively to datasets across different types, even with a small loss.

Applications Across Domains: A Closer Look -Ensemble Techniques
Ensemble Techniques-Although we have broadly noted the general applicability of an ensemble approach in some sense, there are several, perhaps special applications in which incorporating mechanisms from ensemble technology has borne surprisingly close (relative to that particular part of the discourse) attention in a specific area of research.
Ensemble methods are frontrunners in predictive modelling in medicine. Model ensembles are employed, for example in the oncology area to solve problems of genomic data in risk prediction for cancer predisposition, prediction of the probability of a mutation and tailoring of personalized treatment. Besides the results of the different epidemiological models for epidemic prediction, ensembles of results coming from the models. They are also used to compute reliable estimates of disease spread, and thus resource use [6].
Ensembles in finance enhance the portfolio optimization process, in which the balance between risk and return of the mix of assets to be implemented is to be settled. Ensemble-based techniques make use of historical, macroscopic conditions of the state-of-the-art macroeconomic environment as well as real-time market information in building complex investment strategies. Ensembles combine one type of anomaly detection algorithm and one type of classification model to optimize the performance of fraud detection with regards to high sensitivity and high specificity.
Employed for climate and weather predictions in environmental sciences, ensembles are the tools of the trade. Ensemble is an effective technique when the outputs of a number of simulations are combined to produce a more complete description of climate and extreme weather1,2,3. These insights inform policy decisions and disaster preparedness strategies.
Ensemble models are used in education in two ways to actually predict student success and also to guide personalized pathways. These models built upon historical, test and engagement data can identify students who are likely to experience adverse learning trajectories and provide a call to school interventions [25].
In addition, the ensemble approach plays a significant role in the fields of recommendation, e-commerce and marketing etc. (equivalent to amazon, netflix) to replicate user behavior trends, choice behavior and history, ensembles are incorporated to provide “personalized” recommendations, i.e., quality recommendations. This not only matters for the user experience, but for the economy as well, the technology can be made even better.
The Role of Data in Ensemble Success -Ensemble Techniques
Ensemble Techniques-Data quality and data size are the key factors which can lead to the outcome of ensemble method. The quality of the data with which the resulting models can deal, is a quality of the models to not arbitrarily pull spurious patterns, but rather to pull informative ones, and there is a sufficiently large number of samples to avoid overfitting without sacrificing the capacity for generalization.
Comprehensive data preprocessing is a critical step in making data available for ensemble learning. The fundamental modeling is an imputation, outlier removal, and categorical variable encoding type preprocessing to produce acceptable quality data for training the models.
Feature selection and engineering also significantly impact ensemble performance. Practitioners can enhance the learning of the model by determining which of the features is most discriminative and by developing new features whose definition reflects the latent relationships. In particular, ensembles are suited for dimensional data, (possibly) high-dimensional, as the use of ensembles can lead to a form of underfitting.
Evaluating Ensemble Models
Performance measures and validation methods for an ensemble model need to be adequately addressed. Classification is, in general, clinically assessed using accuracy, precision, recall, and F1 score, while the regression problem is assessed using the mean squared error (MSE) and mean absolute error (MAE).
Cross-validation is a popular method to estimate ensemble performance. Using k-fold cross-validation, whichtrains the model stepwise on each of the folds, cross-validation guarantees an accurate generalization to new data. Furthermore, this approach can also provide more reliable model performance estimation of the actual performance of the model in actual-world applications rather than the train-test split in one shot.
Performance evaluations of ensemble models also involve diversity and contribution analysis. Prediction heterogeneity between base models are evaluated and contribution analysis measures the contribution of each of the base models to the ensemble prediction. In addition to exhibiting the power of the ensemble, the proposed metrics also guide the adjustment/adaptation of the ensemble in order to improve the response.
Challenges and Limitations in Practice –Ensemble Techniques
Computational cost continues to be one of the major bottlenecks, particularly for large scale ensembles, deep neural network models, etc. The execution of ensemble models and the averaging of their highest performance also involve consuming much of the computational resources, and, as a result, ensembles are practically impossible to realize in resource-constrained settings.
Hyperparameter tuning is another critical challenge. In order for the small base model to work as it should do and for the ensemble as it should do, the small base model and the ensemble should be well fitted. It is, furthermore, extremely long-lived and requires a large and ungainly experiment. Automated machine learning (AutoML) tools are increasingly being utilized for this task, however, the process itself is limited.
Ensemble interpretability is gaining popularity both inside and outside of applications including health care and finance, where it is necessary to understand the reasonings behind the predictions. ProcedureMethods, like feature importance analysis or SHAP values, can potentially tell us something about interpretability, but these types of models tend to be too simple as compared with even a very compact model like a decision tree.
Emerging Trends in Ensemble Techniques
The future of ensemble methodology is innovation and integration. There is a growing adoption of deep ensembles, that is, a set of heterogeneous deep learning models. Deep ensembles have the feature of strong ability to train from high dimension and complicated data set (e.g., images, text) and transfer to computer vision and natural language processing domains.
Unsupervised learning to ensembles is the trend. Clustering and dimensionality reduction methods enable ensembles to harness the performance of unlabeled data to improve the prediction abilities of an individual estimator’s performance. Semi-supervised ensembles, which collect evidence of information from labeled and unlabel-ed data, become more and more prevalent as labeled information is too costly.
Ensemble methods are also applied to the edge computing and the Internet of Things (IoT) applications. Lightweight ensembles are being designed for low power electronics, and may be utilised for real-time decision making applications within the smart city, connected car, etc.
Conclusion: Harnessing the Power of Ensemble Techniques
Ensemble methods are the state of the art in machine learning innovation that brings the best of multiple models to bear on performance, achieving extraordinary accuracy and robustness. Thanks to their ability to handle heterogeneous data, to learn complex patterns and to perform well on generalization tasks, they are an essential component of the working repertoire of data scientists as well as machine learning researchers.
If one understands the functioning of the subsystem, the modality that is used and the optimal practices for ensemble methods, then ensemble methods can be used at their full potential and even those that appeared to be “incomputable” problems can be solved with confidence. Applications of machine learning, and so on, will be developed down from more technical advances to the ensemble state.
4 thoughts on “Ensemble Techniques in ML ( Classification/Regression)”