Model retraining in machine learning (ML) is the process of updating an existing model to maintain or improve its performance over time as new data becomes available. It is essential because models often degrade in performance due to changes in the underlying data (known as data drift), evolving patterns, or changing external factors. Retraining ensures that the model remains relevant and accurate in real-world applications.
Model retraining in machine learning: What exactly is it?
Model retraining is the process of upgrading a previously deployed machine learning model with new data. This can be done manually or automatically as part of the MLOps techniques. In MLOps, Continuous Training (CT) refers to the monitoring and automatic retraining of an ML model. Model retraining allows the model in production to produce the most accurate predictions using the most recent data.
Model retraining in machine learning does not change the model’s parameters or variables. It adapts the model to the current data, ensuring that the existing parameters produce healthier and more up-to-date results.This enables businesses to efficiently monitor and continuously retrain their models for the most accurate predictions.
Model retraining in machine learning-Why is model retraining necessary?
As the business environment and data change, your ML models’ prediction accuracy will begin to decline in comparison to their performance during testing. This is called model drift and it refers to the degradation of ML model performance over time. Retraining is necessary to avoid drift and ensure that models in production produce healthy outcomes.
Model Retraining in Machine Learning -There are two basic model drift types:
Model retraining in machine learning -There are two main model drift types:
Model Retraining – Concept Drift happens when the relationship between the input and target variables varies over time. Because the description of what we wish to predict changes, the model produces erroneous results.
Data drift occurs when the qualities of the input data vary. Customer behaviors change over time, and the model’s failure to adjust to change is one example.
Model retraining in machine learning-What should be retrained?
How much data will be retrained is an important consideration. If a concept drift has happened and the previous dataset does not match the new environment, it is preferable to replace the complete dataset. This is known as batch or offline learning.
Model retraining in machine learning – However, retraining the model with a completely new dataset can be expensive and generally unneeded if your model has no concept drift. If there is a steady stream of fresh training data, you may use online learning to continuously retrain the model by specifying a time frame that includes new data while excluding old data. For example, you can retrain your model on a regular basis using the most recent dataset spanning the previous 12 months.
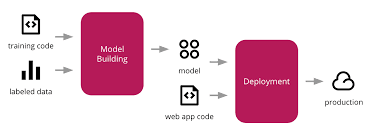
Model retraining in machine learning-When should the models be retrained?
Depending on the business use case, approaches for retraining a model include:
Model retraining in machine learning -In machine learning, model retraining is done periodically. This method involves retraining the model at a time period that you set. Periodic retraining is important when the underlying data changes over time. However, frequent retraining can be computationally expensive, thus selecting the appropriate time interval is critical.
Trigger-based retraining: This method involves determining performance thresholds.
Model retraining in machine learning -When to Retrain a Model
Model retraining can be triggered in several scenarios:
Data Drift: However, as time goes by, the statistical properties of the data used as input vary. For example, customer patterns (and may also emerge) behavior(s) might change, or, entirely new patterns might arise. Detecting data drift automatically is crucial, and models should be retrained when a significant drift is detected.
Concept Drift: When the mapping relationship between input features and target variables is shifted. For instance, a sales predicting model with marketing strategy input may not perform well when new marketing efforts appear or the market changes.
Model Performance Degradation: Continuous tracking of model performance metrics (e.g., accuracy, F1-score) is of paramount importance. If performance falls below a set threshold, that is a signal of the need for a new retraining.
Periodic Retraining: Some organizations schedule model retraining at regular intervals (daily, weekly, monthly) to keep models up to date, even in the absence of detectable performance drops.
New Data Availability: However, when sufficiently new data is acquired (i.e., after the release of a product or the market change), retraining may be required to incorporate the new data and to modify it into predictions.
2. Model retraining in machine learning-Types of Retraining
There are a number of retaning strategies, taking into account models, problems, and data availability:.
Full Retraining: This includes the need to retrain the model from the ground up using old and new data. Although computationally intensive, it is useful if new data reflects substantial shift in the distribution of data.
Incremental Learning: Certain algorithms (such as online learning models) can be updated incrementally (i.e., new data can be used to update the model without retraining the entire model). Algorithms such as SGD (Stochastic Gradient Descent), Naive Bayes, and certain varieties of decision trees are capable of such.
Fine-Tuning: In other situations, rather than retraining from the beginning, the model is fine-tuned on new data. Eg, in deep learning it is possible to read the weights from a pre-trained model with on new data and freeze part of the older layers to maintain learned features.
3. In machine learning-based diagnostics, model retraining-Model Retraining-plays a crucial role.
The general steps involved in retraining a model are:
Data Collection and Preprocessing: Data Collection and Preprocessing:
Gather new data from recent events or interactions.
Process the new data through the same data cleaning, transformation and validation process as the original data set.
Merge new data with existing historical data if full retraining is performed, or use only the new data for fine-tuning or incremental learning.
Feature Engineering: Feature Engineering:
The feature set is then recreated or updated using the new data. That the same feature transformation is applied to keep between the old and the new data consistent.
Model Training: Model Training
Train the model with the updated dataset (either complete training (whole data used at a time) or onestep/fine-tuning).
Applying cross-validation to the retrained model to validate its performance and to guarantee its generalization for unseen data.
Evaluation and Comparison: Evaluation and Comparison:
Compares the retrained model with the original model in terms of important performance metrics such as accuracy, precision, recall, F1-score or MSE.
Compare performance using both new and old data to verify that the model is better than its previous iteration and does not overfit to new data.
Deployment: Deployment:
Deploy the retrained model if the retrained model has signs of improvement. This may include a rollout of a model in stages (canary or A/B tests) to guarantee an easy adoption.
In the case that, for example, the new model performs poorly, the old model is not retired and serves as a fallback option.
Monitoring and Continuous Feedback: Monitoring and Continuous Feedback:
After deployment, it’s necessary to monitor the production behaviour of the new model. Watch out for the possibility of a new data drift or of a new concept drift and configure automated alert in case of a new model poor performance.

4. Model retraining in machine learning Challenges in Model Retraining
Data Drift Detection: Detecting data drift is not always straightforward. There is the need of continuous supervision of the statistical characteristics of the received data. Methods such as distribution comparison (e.g., KL divergence, Jensen-Shannon divergence) can also be useful.
Infrastructure Costs: Full retraining can be computationally demanding, especially in the case of large models such as deep learning networks. Organisations require scalable infrastructure to enable retraining without compromising the other operation.
Version Control: Keeping track of several variants of the model and maintainability is also difficult, especially if the model is used with old and new data. Tools such as MLflow, DVC, and Kubeflow assist with model versioning.
Overfitting to Recent Data: During the retraining process, there is a risk of overfitting to the most recent data if it is assigned too much weight. Balancing of old and new data during training should be avoided for this.
Regulatory and Compliance Issues: Retraining can influence the interpretability of the model, fairness, and compliance with applicable industry regulations (e.g., GDPR). Models have to be updated in a translucent and responsible manner.
5. Model Retraining in Machine Learning-Automation Tools
There are several tools that can help automate the retraining process in machine learning pipelines:.
Kubeflow Pipelines: A tool that enables the automation and management of model retraining work flow, from data ingestion to model deployment.
MLflow: Used in monitoring the machine learning lifecycle, such as experiment logging, versioning and model deployment.
Tecton: A feature store for keeping features consistent between training and inference processes and for supporting retraining with consistency.
SageMaker Pipelines: AWS provides services for managing and automating model retraining in the cloud.
Airflow: A workflow orchestration tool that can be used to schedule and automate retraining tasks in a machine learning pipeline.
6. Model Retraining-Best Practices for Model retraining in machine learning
- Set Retraining Triggers: Define when a model should be retrained. Data drift detection, performance monitoring, or schedule-based alert functions to guarantee timely updates.
- Version Control and Rollbacks: Always version your models and be able to roll back to a previous version in case the newly retrained model underperforms in production.
- Use Model Explainability Tools: Following retraining, employ explanation tools such as LIME or SHAP to understand the rationale behind the new model’s decision, as well as to properly guide it in line with business ambitions and ethical principles.
- Model Performance Tests: Before deploying an retrained model, submit the model to as many tests as possible using both old and new data, to determine if it degrades the model’s performance on any substantial data slice.
Challenges in Model Retraining
Model retraining is not without its challenges. Implementing effective retraining workflows requires addressing several complexities:
1. Data Quality and Availability
Retraining depends on the availability of high-quality, labeled data. Downsampled image, data quality problem, or missing label can cause overfitting, bias, low model performance, and so on.
2. Infrastructure Requirements
Retraining models, especially large ones, demands significant computational resources. Representations of elastic scaling of infrastructure (e.g., GPUs, TPUs, distributed cloud computing) are required to scale out the computation elastically.
3. Version Control and Reproducibility
It is of interest being able to identify which models are actually being employed, and to reproduce the computed outputs. However, this can become an issue if version definition is not always applied (i.e., in the case of the most straightforward scenario, a version with the best fit may be retained based on the criteria).
4. Automation and Monitoring
Automation of the retraining pipeline necessitates powerful pipelines that are equipped with built in recoverys and retraing monitoring systems must be created that can be used to identify the time at which retraing should be applied.
5. Avoiding Overfitting
Overfitting (i.e., the regression model is too specific to the training data set and not specific to the future data set) can occur when the subordinate is retrained using insufficient/unusual training set data.
Types of Model Retraining
The retraining strategy of the model is data driven, with respect to the data that is processed and performance requirements. Here are some common approaches:
1. Periodic Retraining
In periodic retraining the model is retrained at regular intervals (e.g. Regardless of how it functions, day term, week atom, month atom). Such an method can be adopted when some data patterns (e.g., retail market sales forecast) are available.
2. Performance-Based Retraining
Performance-based retraining is the practice of monitoring performance (e.g., accuracy) while working in a production environment. If the metrics reach a threshold set, retraining starts. This approach is particularly suitable for applications prone to data drift, e.g., fraud detection.
3. Continuous Retraining
Continuous retraining herein referred to as online learning) retrains the model online as incoming data is exposed at the time. This technique is of great interest for an on demand and real time system, such as a recommendation engine or a stock market predictor, etc.
4. Event-Driven Retraining
That event-driven modeling is started by specific events, for example, the introduction of a new product line or the radical change in customer thinking. This kind of procedure is often used in interactive applications such as, web shops, or marketing loops.
Key Steps in Model Retraining
1. Data Collection and Preprocessing
Knowledge, unless already in the production environment or else, is acquired. CNS data should be stereotyped, normalized, and mapped (in a way that is very similar to what is assumed at the training data). Preprocessing ensures consistency and prevents errors during retraining.
2. Feature Engineering
The ability to retrain is also an opportunity that comes up to rethink and do part all over again feature engineering. When new features are added, or the features themselves are modified and improved, performance can be greatly enhanced.
3. Data Splitting

There is a division into the training set, the validation set and the test set with respect to the extended data set. Attentional splitting is necessary for both preventing data leakage and biased experiment assessment.
4. Model Training
The model is retrained using the updated dataset. Moreover, hyperparameter tuning may be used to adjust not only the higher performing optimization, but more importantly when the data distribution has been drastically changed.
5. Evaluation and Benchmarking
Retrained models are compared against benchmarks defined at the time of initial model release. Metrics (accuracy, precision, recall, F-1-score and RMSE (Root Mean Square Error) used as measures of comparison between the retrained model and the other two models.
6. Version Control and Deployment
The retrained model is versioned and deployed to production. Proper tracking of model or data change is a critical factor to enable traceability and replication.
7. Monitoring and Feedback
Once deployed, the retrained model’s performance is monitored continuously. Feedback from humans or automated processes can be used for loops of iterative retraining.
Best Practices for Model Retraining
Automate Retraining Pipelines
Design and implement, through the use of tools like Apache Airflow, Kubeflow, or MLflow, automated retraining pipelines. Such pipelines are not limited to learning data loading, preprocessing and training deploying model steps but are capable of accomplishing all these steps automatically, with a limited number of steps on the user side.
Monitor Key Metrics
Establish clear thresholds for performance metrics and data drift. Autopilone detection systems are required to warn teams when training/updating occurs.
Use Incremental Learning
As in the case of applications requiring an ongoing update, consider models with an incremental learning. Neural networks with algorithms (such as Stochastic Gradient Descent (SGD) or Online Decision Trees) can be made (recast) to update only, rather than training from scratch.
Validate with Real-World Data
Train&retrained models on data collected at production level (eg. In the validation stage, a deep learning model acts very robustly and in realistic settings.
Maintain Transparency
Store all the retraining loops, input, changes and performance information. This transparency is important for debugging, compliance, and stakeholder reporting.
Real-World Applications of Model Retraining
Healthcare
When such models trained on the detection of the presence or absence of abnormality in x-ray or mr are needed to be retrained on a regular basis, then such retrained models must be re-trained to incorporate additional imaging modalities or point of care guidelines.
Retail
Recommendation models are continually retrained by the vendors as a response to each consumer behavior, seasonal variation, and product availability.
Financial Services
Fraud detection models need to be retrained on an ongoing basis as patterns of fraud and fraud schemes change and evolve.
Autonomous Vehicles
Autonomous vehicle systems are always operating, developing new perception and control algorithms, so as to successfully operate in the un- knowable real world and its boundary conditions in test and operation.
Future Trends in Model Retraining
1. Federated Retraining
FL enables the model to be retrained on a growing fraction of distributed data sources without any data harmonization [1]. Yet, the same method is also especially relevant to domains where privacy violations can be particularly serious i.e., health and finance.
2. Meta-Learning
Learning-how-to-learn (meta-learning) is the investigation of models that can learn themselves to new tasks and new data with little extra training.
3. Explainable Retraining
In view of increasing demand for interpretable AI, one cannot be far behind in the conjecture that reanalyzing pipelines provide a way to ensure retrained models are no longer interpretable and also lack spurious bias.
Conclusion
Model retraining is an important part of the process for taking machine learning systems used in one environment into a new one. Through the use of organized workflows, smart applications, and by adhering to best practices, companies are able to guarantee that their models are accurate, robust and applicable to business needs. With machine learning’s rapid evolution to often demand rapid retuning, its ability to be retuned rapidly will become increasingly important, and therefore will play a critical role in the overall effectiveness of an AI deployment.