One hot encoding is a technique for representing categorical variables as numerical values in a machine learning model.
Introduction
ML is built upon the power of data, which can turn raw data into useful information. However, for this paradigm change data have to be structured and visualized in a way that is suitable for computational models. As numerical data tends to neatly integrate into machine learning pipelines, categorical data is not only challenging but also problematic. One-hot encoding also serves as an effective choice to transform categorical variables in a numerical way without introducing any other ordinal relationship.
In this paper, one-hot encoding is investigated in detail, both theoretically, and empirically, and by its application, and applications-limitations. In addition, it presents state-of-the-art schemes, real-world applications, and comparative performance against other encoding schemes. By the end of this discussion, readers will understand how one-hot encoding has established itself as a bedrock for modern data science.
What is One-Hot Encoding?
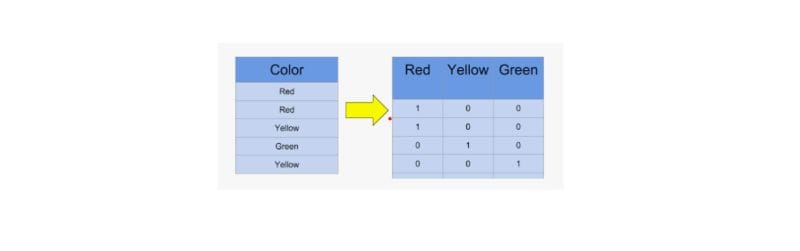
One-hot encoding is a categorical data transformation technique, by which a category label is represented, sequentially, by a binary vector. Each vector represents binary presence or absence of a category for a specific observation. With respect to ordinal encoding, in which categorical variables are assigned continuous numerical values that follow an ordinal order, one-hot encoding is such that each category is treated as a different, independent object, with the consequence that an algorithm cannot learn any relationship between them.
• Spring: [1, 0, 0, 0]
• Summer: [0, 1, 0, 0]
• Autumn: [0, 0, 1, 0]
• Winter: [0, 0, 0, 1]
This shift allows machine learning algorithms to process categorical features without bias or ambiguity.
Why is One-Hot Encoding Crucial?
One hot encoding-The strength of one-hot encoding is that it is able to preserve the structure of categorical data and make it good input for machine learning models. Applications (e.g., linear regression, neural networks) are largely function of numerics. Unadjusted categorical data can cause noise and misrepresentation of model predictions as its original form is left unchanged.
As an example, if a model takes ordinal encoded values [1, 2, 3] for granted, a model could be misled into the false conclusion that category 3 is somehow bigger or better than category 1. Avoiding this issue by partitioning each category into an associated binary column allows all categories to be compared on an equal footing.
| Color | OHE |
|---|---|
| Red | [1, 0, 0] |
| Green | [0, 1, 0] |
| Blue | [0, 0, 1] |
Real-World Case Studies and Applications
Case Study 1: Retail Industry
One hot encoding-Companies in the retail industry work with heterogeneous datasets, consisting of, e.g., customer demographics, product categories, and payment types, where terms can be categorical. For example, a web merchandise business could monitor the popularity of a product in various regions. When using one-hot encoding on variables such as “Region” (North, South, East, West) and “Product Type” (Electronics, Clothing, Groceries), the retailer can use machine learning models to forecast demand patterns and manage inventory effectively.
Case Study 2: Fraud Detection in Banking
One hot encoding Categorical variables, e.g., transaction type, merchant category, and location, are known to be addressed by financial institutions on a regular basis. In an effort to detect fraudulent transactions, features of bank variables are preprocessed by using one-hot encoding. Encoded data is then fed into machine learning algorithms in search of fraudulent patterns.
Case Study 3: Natural Language Processing
One hot encoding For categorical labels (e.g., “Positive,” “Negative,” “Neutral” in text classification tasks, one-hot encoding is a common technique. Despite their state-of-the-art status, like word2vec, approaches are still able to be employed for natural language data and yet one-hot encoding continues to be a basic preprocessing step even for limited instances, like sentiment classification or keyword tagging. store the position of the 1s and ignore the 0s.
2. One Hot Encoding in Machine Learning –Curse of Dimensionality
One hot encoding Alternatives to One-Hot Encoding
Even if one-hot encoding is widely used, however, there does not exist an objective method for representing categorical data. Following are some alternatives each with advantages and disadvantages.
1. Label Encoding
For instance, “Red,” “Blue,” and “Green” may be expressed by 1, 2, and 3, respectively. Despite its extreme simplicity and miniaturization, the method can induce ordinal dependencies which may be conflated in machine learning models.
2. Frequency Encoding
Rather than categories, the rate of recurrence in the dataset is considered. As an example, if “Red” is listed l. and “Blue” is listed m., respectively, they are given as 50 and 30, respectively. In this approach, data is obtained on category prevalence, but it fails to obtain information on contextual relationships.
3. Target Encoding
In this approach replacing categories by the mode of the target variable is applied per category. Despite the high sophistication, it is vulnerable to leakage during the training of the model.
4. Embeddings
Embeddings are dense, lower-dimensional representations of categorical variables. Semantic adjunctions between classes can be stored in them, and they are of interest for purposes, e.g., recommendation systems or NLPs. Yet, embedding requires the considerable time of computer instructions and it is a standard for deep learning models.
One Hot Encoding – Machine Learning Drawback:
- Dimensionality Explosion: If the categorical feature has a large number of possible values, the one-hot encoded vectors become very large, which can lead to high memory usage and potentially slow down the training process.
To address this, alternative techniques such as label encoding or embedding (particularly in deep learning) may be employed.
Advantages of One-Hot Encoding
One hot encoding Simplicity and Transparency
One-hot encoding is easy to write and understand, hence it is a common input format for both the beginner and the expert data scientists. The binary columns correspond perfectly to categories and, as a result, contribute to the model’s interpretability.
One hot encoding Broad Applicability
Blending one-hot encoding with as many ML algorithms (linear models/neural networks, to name a few) at this time makes one-hot encoding feasible to use in most of the possible ML applications scenarios.
Prevention of Ordinal Bias -One hot encoding
Strategies that regard categories as separate objects can use one-hot encoding, where there is no implicit dependency and the model does not make any implicit inference on underlying data patterns.

Limitations of One-Hot Encoding
Curse of Dimensionality -One hot encoding
When categorical variables contain a large number of different categories, one-hot encoding can result in an excessive increase of the number of features. This high dimensionality can put a strain on computational resources and lead to a degraded model performance.
Data Sparsity -One hot encoding
The one-hot encoded binary matrix of each sample is inherently sparse, the majority of the entries are zeros. Sparse datasets require specialized handling and can slow down machine learning pipelines.
Loss of Contextual Relationships -One hot encoding
One-hot encoding treats categories in a completely separate manner and hence does not retain any inherent relationship among them. But this semantic similarity is not encoded before in the binary representation.
Best Practices for Implementing One-Hot Encoding -One hot encoding
1. Handle Missing Data First -One hot encoding
Prior to one-hot encoding, missing values in categorical variables should be imputed or sufficiently handled.
2. Use Dimensionality Reduction -One hot encoding
In high-dimensional data, techniques, e.g., principal component analysis (PCA), can both select the number of features, but also encode the relevant information.
3. Optimize for Sparse Matrices -One hot encoding
When used for sparse data, use the libraries or frameworks specifically dedicated to sparse matrix usage to maximise computing efficiency.
4. Combine with Feature Engineering -One hot encoding
Hybrid methods that integrate one-hot encoding and domain-specific feature engineering to represent category relationships are considered.
The Future of One-Hot Encoding -One hot encoding
One-hot encoding is increasingly being abandoned in the evolution process of data science, and other related fields. While it remains a foundational technique, the growing adoption of advanced methods like embeddings and automated feature engineering suggests that its use may become more specialized.
Hybrid strategies using one-hot encoding, in conjunction with other encoding methods, are becoming the most promising approach. These techniques take advantage of the inherent low complexity of one-hot encoding, to overcome its limitations, in order to perform a more complex data preprocessing.
Historical Context of One-Hot Encoding -One hot encoding
Because now one-hot encoding is implicitly linked to machine learning and data preprocessing, its genesis is philosophical. The methodology was originally formed on the basis of binary logic circuits used in computer technology at the turn of the 20th century. In this kind of systems, states or variables were often encoded using binary patterns in order to avoid ambiguous signals and to not be superimposed upon each other.
During the 1980s and 1990s, owing to the successful growth of machine learning, one-hot encoding indeed evolved as a conventional pre-processing pipeline for categorical data. Simplicity and efficiency went hand in hand with the linear models and decision trees that ruled the day. As more advanced techniques have been introduced, it remains useful to use one-hot encoding and it underlines the continued relevance of one-hot encoding in the data scientist’s repertoire.
Deep Dive into Applications -One hot encoding
1. Automotive Industry: Enhancing Connected Vehicle Insights
Cars with connectivity generate an enormous amount of data and of it is categorical (vehicle kind, road condition, driving decision, etc. Recasting this variable in machine-understandable representations makes this variables trainable for the algorithm to identify patterns for predictive maintenance, traffic optimization in intelligent or smart city and self-driving.
For example, a self-driving car processing road category such as “Night Sky,” “Highway,” “Urban,” and “Rural” can be driven with one-hot encoded data to take split-second actions regarding the acceleration, lane changing, and safety procedures.
2. Entertainment and Streaming Services
Platforms like Netflix, Spotify, and YouTube have restrictions about applying one-hot encoding to handle categorical user preference (i.e., genre, language and devices). This encoding allows machine learning models to recommend personalized content, improving user engagement and retention.
For example, a “Genre” feature (e.g., “Comedy,” “Horror,” “Drama” can be one-hot encoded and algorithms can be employed to decide preference for modalities.
3. IoT (Internet of Things)
Units/devices in an IoT ecosystem generate qualitative outputs, such as sensor type, device states or operational mode. One-hot encoding is able to convert this knowledge into a form that can be used by machines for predictive analysis, anomaly identification, and system calibration.
E.g, a smart thermostat posedge and timing states as “Cooling, Heating” and “Off” can be used to forecast energy use patterns using word-hot-encoding the value states, as well as auto-adjust programmable thermostat set points.
Advanced Mathematical Interpretation -One hot encoding
Basic one-hot encoding mathematics is mapping categorical variables to binary matrices, while sophisticated and interpretable mapping looks at vector spaces and matrix transformation.
Vector Representation
One-hot encoding is mapped to a high-dimensional space in which the spatial dimension of the space equals the number of categories with non-overlapping labels. For instance, for four categories (i.e., 4 dimensional space (4D) is the location of the encoded information). Orthogonality of the resulting vectors ensures that no information is shared across categories, in order to maintain feature independence.
Kernel Trick Compatibility
One-hot encoding is in harmony with kernel tricks in one-class SVM, In which the categorical attributes are mapped into higher dimensional spaces to achieve non-linear separability. Since the values of one-hot encoded features have binary nature, there is a small chance of kernel misunderstanding.
Comparison with Advanced Techniques -One hot encoding
1. Entity Embeddings

Entity embeddings, a deep learning-related representation, computes categories in a sparsely low-dimensional vector-like space. These vectors are learned in the course of model training and reflect category similarities, e.g., semantic similarity or contextual relatedness.
As an example, in a dataset with categories “Apple”, “Orange”, and “Banana”, embeddings can be trained to bring together “Apple” and “Orange” closer (because they are fruits with a similar nature) and away from “Banana” (which is a fruit different from the former two).
Entity embeddings are particularly suited for recommendation systems and natural language processing, where latent category relationships contribute to better model performance.
2. Hash Encoding
Hash encoding dimensionality reduction, where categories are mapped to a fixed number of hash buckets. Although this route reduces the curse of dimensionality, it is also susceptible to collisions, i.e., many categories are mapped into the same bucket. That trade-off makes hash encoding feasible for high-cardinality categorical data even if they come with some loss of accuracy.
3. Ordinal Encoding with Constraints
Ordinality within categories can be informative and ordinal encoding (potentially) with domain-specific constraints may be preferable to one-hot encoding. For instance, categories “Beginner,” “Intermediate,” and “Advanced” can be given weights based on the hierarchy they represent, e.g.
Challenges in Specific Industries
Healthcare: Managing High Cardinality -One hot encoding
Healthcare data instances come with the issue of high-cardinality categorical variables (e.g., ICD-10 disease codes). One-hot encoding can explode dimensionality, creating computational challenges. Frequency encoding or target encoding has been widely applied with one-hot encoding to finally obtain a good balance between accuracy and efficiency.
Marketing: Capturing Customer Behavior -One hot encoding
In digital marketing, these/such as type of customer, or types of ad groups are categorical and need to be accurately expressed. One-hot encoding is easily interpretable, but it may lose the ability to model pairwise item relationships in between items within the same family of close categories. This limitation is widely addressed by means of embeddings or clustering-based approaches.
Optimizing One-Hot Encoding Pipelines
1. Dimensionality Reduction
If, in the datasets, high-cardinality variables are included, then dimensionality reduction, like PCA or t-SNE, of a one-hot encoded matrix can be used to go directly to feature space without significant information loss.
2. Sparse Matrix Representations
Using sparse matrix libraries, such as SciPy in Python, memory overheads and computational costs are effectively zeroed when a matrix has a large number of zeros, or when training data contains a large number of zeros.
3. Cross-Validation for Robustness
For the aim of avoiding introducing bias, practitioners can apply cross-validation techniques whereby the data is binned into a training and a validation series. This approach ensures that the encoded features are consistent in the different subsets.
Emerging Trends in Categorical Data Encoding -One hot encoding
AutoML and Encoding Automation
One-hot encoding is also becoming standard building block within the preprocessing pipelines offered by automated machine learning (AutoML) platforms. These platforms also select the alternatives and select the most suitable encoding method based on the dataset characteristics and the prediction goal.
Hybrid Encoding Strategies
Hybrid methods including one-hot encoding-embedding or frequency-based have been increasing in use. These techniques extend the simplicity of one-hot encoding by compensating for at least some of its limitations and towards the development of data preprocessing pipelines that are robust to potentially misleading data segments.
Interpretability in Complex Models
With the consideration of the interpretability of the framework, i.e., a regulation as GDPR or HIPAA, one-hot encoding is the preferred method due to its transparency. In contrast to embeddings, which may need to be augmented by some form of explanation, one-hot encoded features are directly translatable to their original categories, which can be beneficial for interpretability in certain contexts.
Future Directions for One-Hot Encoding -One hot encoding
The several one-hot encoding developments are most necessarily going to result in better integration with leading state-of-the-art preprocessing pipelines. Techniques such as feature selection, dimensionality reduction, and model-based encoding could become ubiquitous in one-hot encoding pipelines.
Also, with increasingly sophisticated machine learning models, one-hot encoding can be explored in hybrid architectures, which integrate traditional machine learning with deep learning to optimally represent categorical information for a variety of architectures.
Expanded Conclusion -One hot encoding
One-hot encoding remains one of the non-aging techniques in the ever-growing, non-stagnant world of machine learning. Its simplicity, effectiveness, and compatibility with various algorithms make it an indispensable tool for data preprocessing. By the process of transforming categorical information into one-hot matrices this link between primitive data and their relevant information in machine learning is built.
However, its limitations underscore the importance of context-aware implementation. In the case of one-hot encoding, for applying one-hot encoding, data scientists must consider a number of factors including dimensionality, sparsity, and category ties. The problem is particularly prominent while examining complementary approaches, such as embeddings, target encoding, or mixed approaches, in which machine learning pipelines can even be improved by providing encoded information that is of a contextually appropriate level with respect to the model’s predictive goals.
One hot encoding As the field advances, one-shot encoding will continue to develop and change while retaining its core idea in its emerging form as well as in its alternatives that demonstrate the potential horizon of machine learning. of which field–pediatric care, marketisation or IoT–by bridging this gap, practitioners can tap into the capabilities of categorical data, to break some boundaries, to create real-world value, and so forth.
Conclusion
One-hot encoding is an underpinning of current machine learning that allows categorical data to smoothly integrate into prediction models. Since it is easy, clear, and general, it has become the de facto method in data science across all industries.
Despite its limitations, the advantage of one-hot encoding promises its value in a dynamically evolving data science world. Through the learning of how it can be utilized, applied and where it is best suited, practitioners are in a position to employ this approach to build powerful and reliable machine learning models. However, as the data magnitude rises, one-hot encoding will continue to be in the spotlight, bridging vocabulary and integeration in the age of artificial intelligence.
1 thought on “One Hot Encoding in Machine Learning”